(cherry picked from commit e11dcc60f2)
use backticks to avoid backslash
(cherry picked from commit 34212791ee)
(cherry picked from commit bde9473c69)
(cherry picked from commit d4deb43084)
(cherry picked from commit 08e91649b0)
(cherry picked from commit 2b988e5415)
[TESTS] auth LinkAccount test coverage (squash)
(cherry picked from commit a2b2e3066b)
(cherry picked from commit 841d1b5073)
(cherry picked from commit 35da630ad8)
(cherry picked from commit caf2dc4fa7)
- Implements https://codeberg.org/forgejo/discussions/issues/32#issuecomment-918737
- Allows to add Forgejo-specific migrations that don't interfere with Gitea's migration logic. Please do note that we cannot liberally add migrations for Gitea tables, as they might do their own migrations in a future version on that table, and that could undo our migrations. Luckily, we don't have a scenario where that's needed and thus not taken into account.
Co-authored-by: Gusted <postmaster@gusted.xyz>
Reviewed-on: https://codeberg.org/forgejo/forgejo/pulls/795
(cherry picked from commit 8ee32978c0)
(cherry picked from commit c240b34f59)
(cherry picked from commit 03936c6492)
(cherry picked from commit a20ed852f8)
(cherry picked from commit 1dfa82676f)
(cherry picked from commit c39ae0bf8a)
(cherry picked from commit cfaff08996)
(cherry picked from commit 94a458835a)
(cherry picked from commit 61a3cf77df)
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
In the original implementation, we can only get the first 30 records of
the commit status (the default paging size), if the commit status is
more than 30, it will lead to the bug #25990. I made the following two
changes.
- On the page, use the ` db.ListOptions{ListAll: true}` parameter
instead of `db.ListOptions{}`
- The `GetLatestCommitStatus` function makes a determination as to
whether or not a pager is being used.
fixed #25990
The API should only return the real Mail of a User, if the caller is
logged in. The check do to this don't work. This PR fixes this. This not
really a security issue, but can lead to Spam.
---------
Co-authored-by: silverwind <me@silverwind.io>
Fix #25934
Add `ignoreGlobal` parameter to `reqUnitAccess` and only check global
disabled units when `ignoreGlobal` is true. So the org-level projects
and user-level projects won't be affected by global disabled
`repo.projects` unit.
Fixes #25918
The migration fails on MSSQL because xorm tries to update the primary
key column. xorm prevents this if the column is marked as auto
increment:
c622cdaf89/internal/statements/update.go (L38-L40)
I think it would be better if xorm would check for primary key columns
here because updating such columns is bad practice. It looks like if
that auto increment check should do the same.
fyi @lunny
This PR
- Fix #26093. Replace `time.Time` with `timeutil.TimeStamp`
- Fix #26135. Add missing `xorm:"extends"` to `CountLFSMetaObject` for
LFS meta object query
- Add a unit test for LFS meta object garbage collection
Before:

After:
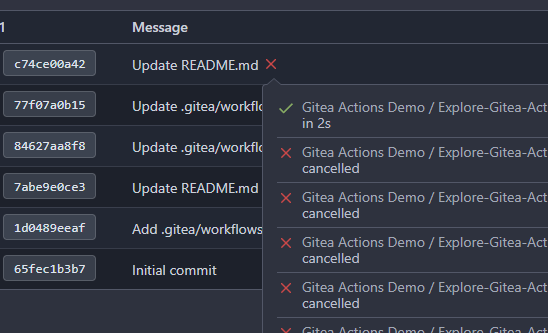
There's a bug in the recent logic, `CalcCommitStatus` will always return
the first item of `statuses` or error status, because `state` is defined
with default value which should be `CommitStatusSuccess`
Then
``` golang
if status.State.NoBetterThan(state) {
```
this `if` will always return false unless `status.State =
CommitStatusError` which makes no sense.
So `lastStatus` will always be `nil` or error status.
Then we will always return the first item of `statuses` here or only
return error status, and this is why in the first picture the commit
status is `Success` but not `Failure`.
af1ffbcd63/models/git/commit_status.go (L204-L211)
Co-authored-by: Giteabot <teabot@gitea.io>
- cancel running jobs if the event is push
- Add a new function `CancelRunningJobs` to cancel all running jobs of a
run
- Update `FindRunOptions` struct to include `Ref` field and update its
condition in `toConds` function
- Implement auto cancellation of running jobs in the same workflow in
`notify` function
related task: https://github.com/go-gitea/gitea/pull/22751/
---------
Signed-off-by: Bo-Yi Wu <appleboy.tw@gmail.com>
Signed-off-by: appleboy <appleboy.tw@gmail.com>
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: delvh <dev.lh@web.de>
Close #24544
Changes:
- Create `action_tasks_version` table to store the latest version of
each scope (global, org and repo).
- When a job with the status of `waiting` is created, the tasks version
of the scopes it belongs to will increase.
- When the status of a job already in the database is updated to
`waiting`, the tasks version of the scopes it belongs to will increase.
- On Gitea side, in `FeatchTask()`, will try to query the
`action_tasks_version` record of the scope of the runner that call
`FetchTask()`. If the record does not exist, will insert a row. Then,
Gitea will compare the version passed from runner to Gitea with the
version in database, if inconsistent, try pick task. Gitea always
returns the latest version from database to the runner.
Related:
- Protocol: https://gitea.com/gitea/actions-proto-def/pulls/10
- Runner: https://gitea.com/gitea/act_runner/pulls/219
To avoid deadlock problem, almost database related functions should be
have ctx as the first parameter.
This PR do a refactor for some of these functions.
Fix #25776. Close #25826.
In the discussion of #25776, @wolfogre's suggestion was to remove the
commit status of `running` and `warning` to keep it consistent with
github.
references:
-
https://docs.github.com/en/rest/commits/statuses?apiVersion=2022-11-28#about-commit-statuses
## ⚠️ BREAKING ⚠️
So the commit status of Gitea will be consistent with GitHub, only
`pending`, `success`, `error` and `failure`, while `warning` and
`running` are not supported anymore.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
current actions artifacts implementation only support single file
artifact. To support multiple files uploading, it needs:
- save each file to each db record with same run-id, same artifact-name
and proper artifact-path
- need change artifact uploading url without artifact-id, multiple files
creates multiple artifact-ids
- support `path` in download-artifact action. artifact should download
to `{path}/{artifact-path}`.
- in repo action view, it provides zip download link in artifacts list
in summary page, no matter this artifact contains single or multiple
files.
Before:
After:

This issue comes from the change in #25468.
`LoadProject` will always return at least one record, so we use
`ProjectID` to check whether an issue is linked to a project in the old
code.
As other `issue.LoadXXX` functions, we need to check the return value
from `xorm.Session.Get`.
In recent unit tests, we only test `issueList.LoadAttributes()` but
don't test `issue.LoadAttributes()`. So I added a new test for
`issue.LoadAttributes()` in this PR.
---------
Co-authored-by: Denys Konovalov <privat@denyskon.de>
Fixes (?) #25538
Fixes https://codeberg.org/forgejo/forgejo/issues/972
Regression #23879#23879 introduced a change which prevents read access to packages if a
user is not a member of an organization.
That PR also contained a change which disallows package access if the
team unit is configured with "no access" for packages. I don't think
this change makes sense (at the moment). It may be relevant for private
orgs. But for public or limited orgs that's useless because an
unauthorized user would have more access rights than the team member.
This PR restores the old behaviour "If a user has read access for an
owner, they can read packages".
---------
Co-authored-by: Giteabot <teabot@gitea.io>
related #16865
This PR adds an accessibility check before mounting container blobs.
---------
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Co-authored-by: silverwind <me@silverwind.io>
This PR will display a pull request creation hint on the repository home
page when there are newly created branches with no pull request. Only
the recent 6 hours and 2 updated branches will be displayed.
Inspired by #14003
Replace #14003
Resolves #311
Resolves #13196
Resolves #23743
co-authored by @kolaente
Add a few extra test cases and test functions for the collaboration
model to get everything covered by tests (except for error handling, as
we cannot suddenly mock errors from the database).
Co-authored-by: Gusted <postmaster@gusted.xyz>
Reviewed-on: https://codeberg.org/forgejo/forgejo/pulls/825
Co-authored-by: Gusted <gusted@noreply.codeberg.org>
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: Giteabot <teabot@gitea.io>
Fix #25558
Extract from #22743
This PR added a repository's check when creating/deleting branches via
API. Mirror repository and archive repository cannot do that.
When branch's commit CommitMessage is too long, the column maybe too
short.(TEXT 16K for mysql).
This PR will fix it to only store the summary because these message will
only show on branch list or possible future search?
Related #14180
Related #25233
Related #22639
Close #19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
releated to #21820
- Split `Size` in repository table as two new colunms, one is `GitSize`
for git size, the other is `LFSSize` for lfs data. still store full size
in `Size` colunm.
- Show full size on ui, but show each of them by a `title`; example:
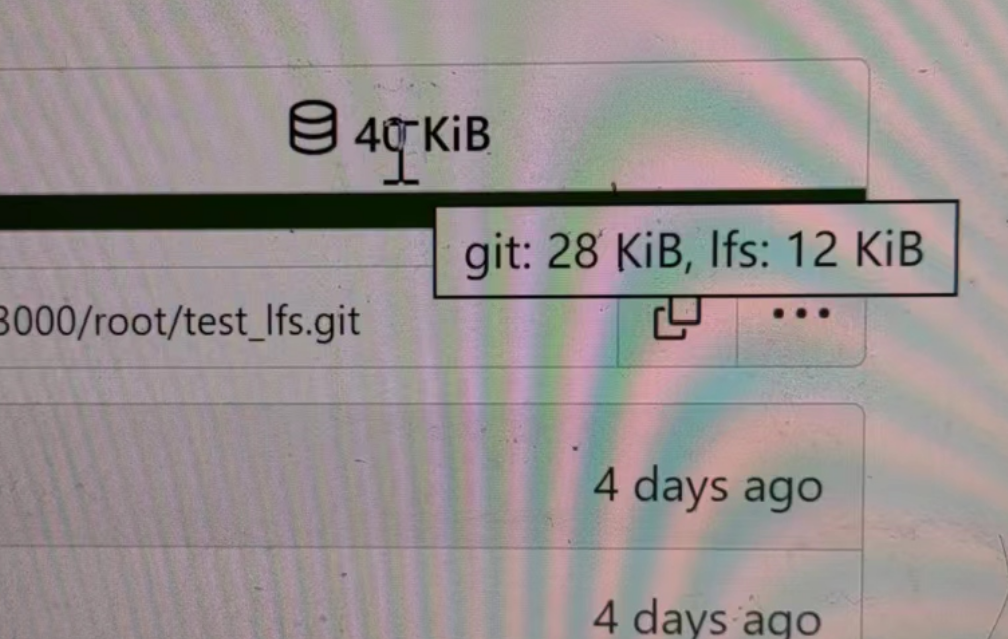
- Return full size in api response.
---------
Signed-off-by: a1012112796 <1012112796@qq.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: DmitryFrolovTri <23313323+DmitryFrolovTri@users.noreply.github.com>
Co-authored-by: Giteabot <teabot@gitea.io>
Fix #25451.
Bugfixes:
- When stopping the zombie or endless tasks, set `LogInStorage` to true
after transferring the file to storage. It was missing, it could write
to a nonexistent file in DBFS because `LogInStorage` was false.
- Always update `ActionTask.Updated` when there's a new state reported
by the runner, even if there's no change. This is to avoid the task
being judged as a zombie task.
Enhancement:
- Support `Stat()` for DBFS file.
- `WriteLogs` refuses to write if it could result in content holes.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
{kind=link}
{kind=link}
{kind=link}