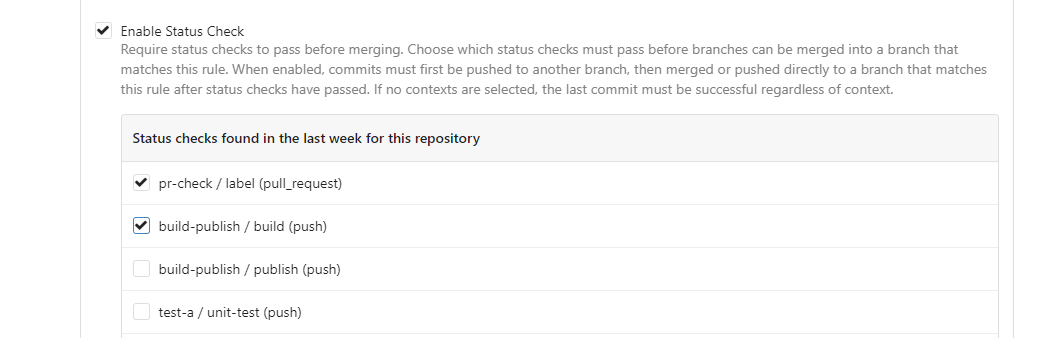
This PR is to allow users to specify status checks by patterns. Users
can enter patterns in the "Status Check Pattern" `textarea` to match
status checks and each line specifies a pattern. If "Status Check" is
enabled, patterns cannot be empty and user must enter at least one
pattern.
Users will no longer be able to choose status checks from the table. But
a __*`Matched`*__ mark will be added to the matched checks to help users
enter patterns.
Benefits:
- Even if no status checks have been completed, users can specify
necessary status checks in advance.
- More flexible. Users can specify a series of status checks by one
pattern.
Before:
After:

---------
Co-authored-by: silverwind <me@silverwind.io>
# ⚠️ Breaking
Many deprecated queue config options are removed (actually, they should
have been removed in 1.18/1.19).
If you see the fatal message when starting Gitea: "Please update your
app.ini to remove deprecated config options", please follow the error
messages to remove these options from your app.ini.
Example:
```
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].ISSUE_INDEXER_QUEUE_TYPE`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].UPDATE_BUFFER_LEN`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [F] Please update your app.ini to remove deprecated config options
```
Many options in `[queue]` are are dropped, including:
`WRAP_IF_NECESSARY`, `MAX_ATTEMPTS`, `TIMEOUT`, `WORKERS`,
`BLOCK_TIMEOUT`, `BOOST_TIMEOUT`, `BOOST_WORKERS`, they can be removed
from app.ini.
# The problem
The old queue package has some legacy problems:
* complexity: I doubt few people could tell how it works.
* maintainability: Too many channels and mutex/cond are mixed together,
too many different structs/interfaces depends each other.
* stability: due to the complexity & maintainability, sometimes there
are strange bugs and difficult to debug, and some code doesn't have test
(indeed some code is difficult to test because a lot of things are mixed
together).
* general applicability: although it is called "queue", its behavior is
not a well-known queue.
* scalability: it doesn't seem easy to make it work with a cluster
without breaking its behaviors.
It came from some very old code to "avoid breaking", however, its
technical debt is too heavy now. It's a good time to introduce a better
"queue" package.
# The new queue package
It keeps using old config and concept as much as possible.
* It only contains two major kinds of concepts:
* The "base queue": channel, levelqueue, redis
* They have the same abstraction, the same interface, and they are
tested by the same testing code.
* The "WokerPoolQueue", it uses the "base queue" to provide "worker
pool" function, calls the "handler" to process the data in the base
queue.
* The new code doesn't do "PushBack"
* Think about a queue with many workers, the "PushBack" can't guarantee
the order for re-queued unhandled items, so in new code it just does
"normal push"
* The new code doesn't do "pause/resume"
* The "pause/resume" was designed to handle some handler's failure: eg:
document indexer (elasticsearch) is down
* If a queue is paused for long time, either the producers blocks or the
new items are dropped.
* The new code doesn't do such "pause/resume" trick, it's not a common
queue's behavior and it doesn't help much.
* If there are unhandled items, the "push" function just blocks for a
few seconds and then re-queue them and retry.
* The new code doesn't do "worker booster"
* Gitea's queue's handlers are light functions, the cost is only the
go-routine, so it doesn't make sense to "boost" them.
* The new code only use "max worker number" to limit the concurrent
workers.
* The new "Push" never blocks forever
* Instead of creating more and more blocking goroutines, return an error
is more friendly to the server and to the end user.
There are more details in code comments: eg: the "Flush" problem, the
strange "code.index" hanging problem, the "immediate" queue problem.
Almost ready for review.
TODO:
* [x] add some necessary comments during review
* [x] add some more tests if necessary
* [x] update documents and config options
* [x] test max worker / active worker
* [x] re-run the CI tasks to see whether any test is flaky
* [x] improve the `handleOldLengthConfiguration` to provide more
friendly messages
* [x] fine tune default config values (eg: length?)
## Code coverage:

Close #24213
Replace #23830
#### Cause
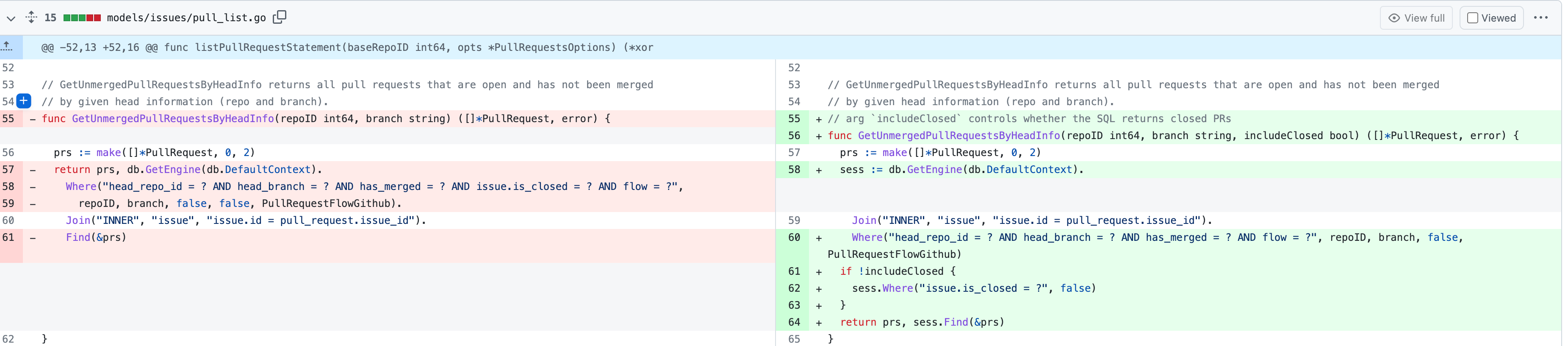
- Before, in order to making PR can get latest commit after reopening,
the `ref`(${REPO_PATH}/refs/pull/${PR_INDEX}/head) of evrey closed PR
will be updated when pushing commits to the `head branch` of the closed
PR.
#### Changes
- For closed PR , won't perform these behavior: insert`comment`, push
`notification` (UI and email), exectue
[pushToBaseRepo](7422503341/services/pull/pull.go (L409))
function and trigger `action` any more when pushing to the `head branch`
of the closed PR.
- Refresh the reference of the PR when reopening the closed PR (**even
if the head branch has been deleted before**). Make the reference of PR
consistent with the `head branch`.
Close #23440
Cause by #23189
In #23189, we should insert a comment record into db when pushing a
commit to the PR, even if the PR is closed.
But should skip sending any notification in this case.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
When emails addresses are private, squash merges always use
`@noreply.localhost` for the author of the squash commit. And the author
is redundantly added as a co-author in the commit message.
Also without private mails, the redundant co-author is possible when
committing with a signature that's different than the user full name and
primary email.
Now try to find a commit by the same user in the list of commits, and
prefer the signature from that over one constructed from the account
settings.
When the base repository contains multiple branches with the same
commits as the base branch, pull requests can show a long list of
commits already in the base branch as having been added.
What this is supposed to do is exclude commits already in the base
branch. But the mechansim to do so assumed a commit only exists in a
single branch. Now use `git rev-list A B --not branchName` instead of
filtering commits afterwards.
The logic to detect if there was a force push also was wrong for
multiple branches. If the old commit existed in any branch in the base
repository it would assume there was no force push. Instead check if the
old commit is an ancestor of the new commit.
Follow #22568
* Remove unnecessary ToTrustedCmdArgs calls
* the FAQ in #22678
* Quote: When using ToTrustedCmdArgs, the code will be very complex (see
the changes for examples). Then developers and reviewers can know that
something might be unreasonable.
* The `signArg` couldn't be empty, it's either `-S{keyID}` or
`--no-gpg-sign`.
* Use `signKeyID` instead, add comment "empty for no-sign, non-empty to
sign"
* 5-line code could be extracted to a common `NewGitCommandCommit()` to
handle the `signKeyID`, but I think it's not a must, current code is
clear enough.
The merge and update branch code was previously a little tangled and had
some very long functions. The functions were not very clear in their
reasoning and there were deficiencies in their logging and at least one
bug in the handling of LFS for update by rebase.
This PR substantially refactors this code and splits things out to into
separate functions. It also attempts to tidy up the calls by wrapping
things in "context"s. There are also attempts to improve logging when
there are errors.
Signed-off-by: Andrew Thornton <art27@cantab.net>
---------
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Co-authored-by: delvh <dev.lh@web.de>
Close #23241
Before: press Ctrl+Enter in the Code Review Form, a single comment will
be added.
After: press Ctrl+Enter in the Code Review Form, start the review with
pending comments.
The old name `is_review` is not clear, so the new code use
`pending_review` as the new name.
Co-authored-by: delvh <leon@kske.dev>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
When fetching remotes for conflict checking, skip unnecessary and
potentially slow writing of commit graphs.
In a test with the Blender repository, this reduces conflict checking
time for one pull request from about 2s to 0.1s.
Close #23027
`git commit` message option _only_ supports 4 formats (well, only ....):
* `"commit", "-m", msg`
* `"commit", "-m{msg}"` (no space)
* `"commit", "--message", msg`
* `"commit", "--message={msg}"`
The long format with `=` is the best choice, and it's documented in `man
git-commit`:
`-m <msg>, --message=<msg> ...`
ps: I would suggest always use long format option for git command, as
much as possible.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
Should call `PushToBaseRepo` before
`notification.NotifyPullRequestSynchronized`.
Or the notifier will get an old commit when reading branch
`pull/xxx/head`.
Found by ~#21937~ #22679.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This PR follows #21535 (and replace #22592)
## Review without space diff
https://github.com/go-gitea/gitea/pull/22678/files?diff=split&w=1
## Purpose of this PR
1. Make git module command completely safe (risky user inputs won't be
passed as argument option anymore)
2. Avoid low-level mistakes like
https://github.com/go-gitea/gitea/pull/22098#discussion_r1045234918
3. Remove deprecated and dirty `CmdArgCheck` function, hide the `CmdArg`
type
4. Simplify code when using git command
## The main idea of this PR
* Move the `git.CmdArg` to the `internal` package, then no other package
except `git` could use it. Then developers could never do
`AddArguments(git.CmdArg(userInput))` any more.
* Introduce `git.ToTrustedCmdArgs`, it's for user-provided and already
trusted arguments. It's only used in a few cases, for example: use git
arguments from config file, help unit test with some arguments.
* Introduce `AddOptionValues` and `AddOptionFormat`, they make code more
clear and simple:
* Before: `AddArguments("-m").AddDynamicArguments(message)`
* After: `AddOptionValues("-m", message)`
* -
* Before: `AddArguments(git.CmdArg(fmt.Sprintf("--author='%s <%s>'",
sig.Name, sig.Email)))`
* After: `AddOptionFormat("--author='%s <%s>'", sig.Name, sig.Email)`
## FAQ
### Why these changes were not done in #21535 ?
#21535 is mainly a search&replace, it did its best to not change too
much logic.
Making the framework better needs a lot of changes, so this separate PR
is needed as the second step.
### The naming of `AddOptionXxx`
According to git's manual, the `--xxx` part is called `option`.
### How can it guarantee that `internal.CmdArg` won't be not misused?
Go's specification guarantees that. Trying to access other package's
internal package causes compilation error.
And, `golangci-lint` also denies the git/internal package. Only the
`git/command.go` can use it carefully.
### There is still a `ToTrustedCmdArgs`, will it still allow developers
to make mistakes and pass untrusted arguments?
Generally speaking, no. Because when using `ToTrustedCmdArgs`, the code
will be very complex (see the changes for examples). Then developers and
reviewers can know that something might be unreasonable.
### Why there was a `CmdArgCheck` and why it's removed?
At the moment of #21535, to reduce unnecessary changes, `CmdArgCheck`
was introduced as a hacky patch. Now, almost all code could be written
as `cmd := NewCommand(); cmd.AddXxx(...)`, then there is no need for
`CmdArgCheck` anymore.
### Why many codes for `signArg == ""` is deleted?
Because in the old code, `signArg` could never be empty string, it's
either `-S[key-id]` or `--no-gpg-sign`. So the `signArg == ""` is just
dead code.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Our trace logging is far from perfect and is difficult to follow.
This PR:
* Add trace logging for process manager add and remove.
* Fixes an errant read file for git refs in getMergeCommit
* Brings in the pullrequest `String` and `ColorFormat` methods
introduced in #22568
* Adds a lot more logging in to testPR etc.
Ref #22578
---------
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
The code for checking if a commit has caused a change in a PR is
extremely inefficient and affects the head repository instead of using a
temporary repository.
This PR therefore makes several significant improvements:
* A temporary repo like that used in merging.
* The diff code is then significant improved to use a three-way diff
instead of comparing diffs (possibly binary) line-by-line - in memory...
Ref #22578
Signed-off-by: Andrew Thornton <art27@cantab.net>
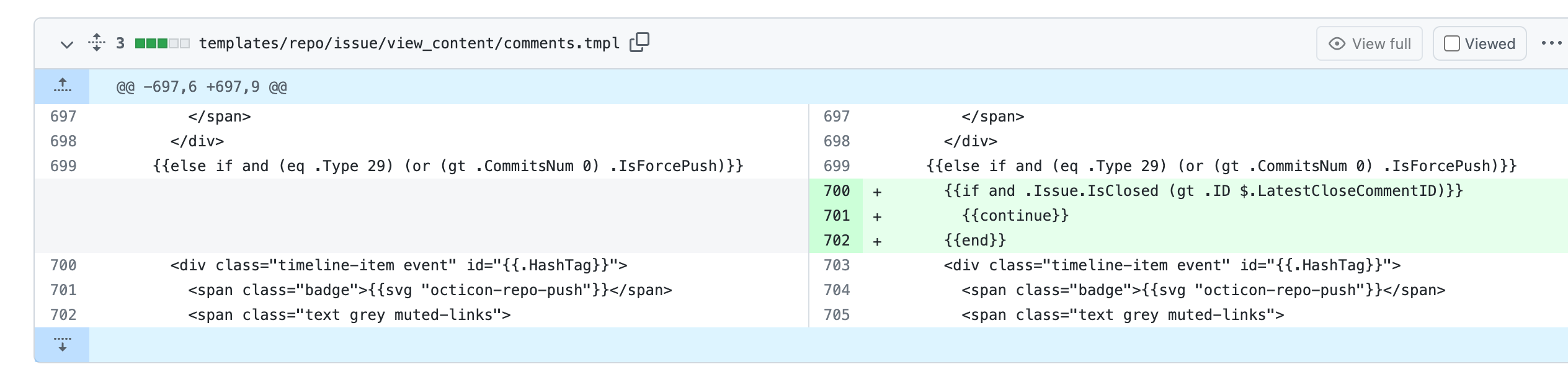
The `commit_id` property name is the same as equivalent functionality in
GitHub. If the action was not caused by a commit, an empty string is
used.
This can for example be used to automatically add a Resolved label to an
issue fixed by a commit, or clear it when the issue is reopened.
The update by rebase code reuses the merge code but shortcircuits and
pushes back up to the head. However, it doesn't set the correct pushing
environment - and just uses the same environment as the base repo. This
leads to the push update failing and thence the PR becomes out-of-sync
with the head.
This PR fixes this and adjusts the trace logging elsewhere to help make
this clearer.
Fix #18802
Signed-off-by: Andrew Thornton <art27@cantab.net>
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
Swallow error just like in #20839, for the case where there is no
protected branch.
Fixes #20826 for me, though I can't tell if this now covers all cases.
This PR introduce glob match for protected branch name. The separator is
`/` and you can use `*` matching non-separator chars and use `**` across
separator.
It also supports input an exist or non-exist branch name as matching
condition and branch name condition has high priority than glob rule.
Should fix #2529 and #15705
screenshots
<img width="1160" alt="image"
src="https://user-images.githubusercontent.com/81045/205651179-ebb5492a-4ade-4bb4-a13c-965e8c927063.png">
Co-authored-by: zeripath <art27@cantab.net>
After #22362, we can feel free to use transactions without
`db.DefaultContext`.
And there are still lots of models using `db.DefaultContext`, I think we
should refactor them carefully and one by one.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
For a long time Gitea has tested PR patches using a git apply --check
method, and in fact prior to the introduction of a read-tree assisted
three-way merge in #18004, this was the only way of checking patches.
Since #18004, the git apply --check method has been a fallback method,
only used when the read-tree three-way merge method has detected a
conflict. The read-tree assisted three-way merge method is much faster
and less resource intensive method of detecting conflicts. #18004 kept
the git apply method around because it was thought possible that this
fallback might be able to rectify conflicts that the read-tree three-way
merge detected. I am not certain if this could ever be the case.
Given the uncertainty here and the now relative stability of the
read-tree method - this PR makes using this fallback optional and
disables it by default. The hope is that users will not notice any
significant difference in conflict detection and we will be able to
remove the git apply fallback in future, and/or improve the read-tree
three-way merge method to catch any conflicts that git apply method
might have been able to fix.
An additional benefit is that patch checking should be significantly
less resource intensive and much quicker.
(See
https://github.com/go-gitea/gitea/issues/22083\#issuecomment-1347961737)
Ref #22083
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
Moved files in a patch will result in git apply returning:
```
error: {filename}: No such file or directory
```
This wasn't handled by the git apply patch code. This PR adds handling
for this.
Fix #22083
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: techknowlogick <techknowlogick@gitea.io>
Change all license headers to comply with REUSE specification.
Fix #16132
Co-authored-by: flynnnnnnnnnn <flynnnnnnnnnn@github>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
This PR adds a context parameter to a bunch of methods. Some helper
`xxxCtx()` methods got replaced with the normal name now.
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Fix #19513
This PR introduce a new db method `InTransaction(context.Context)`,
and also builtin check on `db.TxContext` and `db.WithTx`.
There is also a new method `db.AutoTx` has been introduced but could be used by other PRs.
`WithTx` will always open a new transaction, if a transaction exist in context, return an error.
`AutoTx` will try to open a new transaction if no transaction exist in context.
That means it will always enter a transaction if there is no error.
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: 6543 <6543@obermui.de>
I found myself wondering whether a PR I scheduled for automerge was
actually merged. It was, but I didn't receive a mail notification for it
- that makes sense considering I am the doer and usually don't want to
receive such notifications. But ideally I want to receive a notification
when a PR was merged because I scheduled it for automerge.
This PR implements exactly that.
The implementation works, but I wonder if there's a way to avoid passing
the "This PR was automerged" state down so much. I tried solving this
via the database (checking if there's an automerge scheduled for this PR
when sending the notification) but that did not work reliably, probably
because sending the notification happens async and the entry might have
already been deleted. My implementation might be the most
straightforward but maybe not the most elegant.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
When merge was changed to run in the background context, the db updates
were still running in request context. This means that the merge could
be successful but the db not be updated.
This PR changes both these to run in the hammer context, this is not
complete rollback protection but it's much better.
Fix #21332
Signed-off-by: Andrew Thornton <art27@cantab.net>
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Some repositories do not have the PullRequest unit present in their configuration
and unfortunately the way that IsUserAllowedToUpdate currently works assumes
that this is an error instead of just returning false.
This PR simply swallows this error allowing the function to return false.
Fix #20621
Signed-off-by: Andrew Thornton <art27@cantab.net>
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
There is a subtle bug in the code relating to collating the results of
`git ls-files -u -z` in `unmergedFiles()`. The code here makes the
mistake of assuming that every unmerged file will always have a stage 1
conflict, and this results in conflicts that occur in stage 3 only being
dropped.
This PR simply adjusts this code to ensure that any empty unmergedFile
will always be passed down the channel.
The PR also adds a lot of Trace commands to attempt to help find future
bugs in this code.
Fix #19527
Signed-off-by: Andrew Thornton <art27@cantab.net>
* Fixes issue #19603 (Not able to merge commit in PR when branches content is same, but different commit id)
* fill HeadCommitID in PullRequest
* compare real commits ID as check for merging
* based on @zeripath patch in #19738
* Check if project has the same repository id with issue when assign project to issue
* Check if issue's repository id match project's repository id
* Add more permission checking
* Remove invalid argument
* Fix errors
* Add generic check
* Remove duplicated check
* Return error + add check for new issues
* Apply suggestions from code review
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
Co-authored-by: Gusted <williamzijl7@hotmail.com>
Co-authored-by: KN4CK3R <admin@oldschoolhack.me>
Co-authored-by: 6543 <6543@obermui.de>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}