Refactor Hash interfaces and centralize hash function. This will allow
easier introduction of different hash function later on.
This forms the "no-op" part of the SHA256 enablement patch.
The function `GetByBean` has an obvious defect that when the fields are
empty values, it will be ignored. Then users will get a wrong result
which is possibly used to make a security problem.
To avoid the possibility, this PR removed function `GetByBean` and all
references.
And some new generic functions have been introduced to be used.
The recommand usage like below.
```go
// if query an object according id
obj, err := db.GetByID[Object](ctx, id)
// query with other conditions
obj, err := db.Get[Object](ctx, builder.Eq{"a": a, "b":b})
```
The git command may operate the git directory (add/remove) files in any
time.
So when the code iterates the directory, some files may disappear during
the "walk". All "IsNotExist" errors should be ignored.
Fix #26765
This PR reduces the complexity of the system setting system.
It only needs one line to introduce a new option, and the option can be
used anywhere out-of-box.
It is still high-performant (and more performant) because the config
values are cached in the config system.
This PR removed `unittest.MainTest` the second parameter
`TestOptions.GiteaRoot`. Now it detects the root directory by current
working directory.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
This PR adds a new field `RemoteAddress` to both mirror types which
contains the sanitized remote address for easier (database) access to
that information. Will be used in the audit PR if merged.
Part of #27065
This reduces the usage of `db.DefaultContext`. I think I've got enough
files for the first PR. When this is merged, I will continue working on
this.
Considering how many files this PR affect, I hope it won't take to long
to merge, so I don't end up in the merge conflict hell.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Unfortunately, when a system setting hasn't been stored in the database,
it cannot be cached.
Meanwhile, this PR also uses context cache for push email avatar display
which should avoid to read user table via email address again and again.
According to my local test, this should reduce dashboard elapsed time
from 150ms -> 80ms .
Fix #24662.
Replace #24822 and #25708 (although it has been merged)
## Background
In the past, Gitea supported issue searching with a keyword and
conditions in a less efficient way. It worked by searching for issues
with the keyword and obtaining limited IDs (as it is heavy to get all)
on the indexer (bleve/elasticsearch/meilisearch), and then querying with
conditions on the database to find a subset of the found IDs. This is
why the results could be incomplete.
To solve this issue, we need to store all fields that could be used as
conditions in the indexer and support both keyword and additional
conditions when searching with the indexer.
## Major changes
- Redefine `IndexerData` to include all fields that could be used as
filter conditions.
- Refactor `Search(ctx context.Context, kw string, repoIDs []int64,
limit, start int, state string)` to `Search(ctx context.Context, options
*SearchOptions)`, so it supports more conditions now.
- Change the data type stored in `issueIndexerQueue`. Use
`IndexerMetadata` instead of `IndexerData` in case the data has been
updated while it is in the queue. This also reduces the storage size of
the queue.
- Enhance searching with Bleve/Elasticsearch/Meilisearch, make them
fully support `SearchOptions`. Also, update the data versions.
- Keep most logic of database indexer, but remove
`issues.SearchIssueIDsByKeyword` in `models` to avoid confusion where is
the entry point to search issues.
- Start a Meilisearch instance to test it in unit tests.
- Add unit tests with almost full coverage to test
Bleve/Elasticsearch/Meilisearch indexer.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
When branch's commit CommitMessage is too long, the column maybe too
short.(TEXT 16K for mysql).
This PR will fix it to only store the summary because these message will
only show on branch list or possible future search?
Related #14180
Related #25233
Related #22639
Close #19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
releated to #21820
- Split `Size` in repository table as two new colunms, one is `GitSize`
for git size, the other is `LFSSize` for lfs data. still store full size
in `Size` colunm.
- Show full size on ui, but show each of them by a `title`; example:
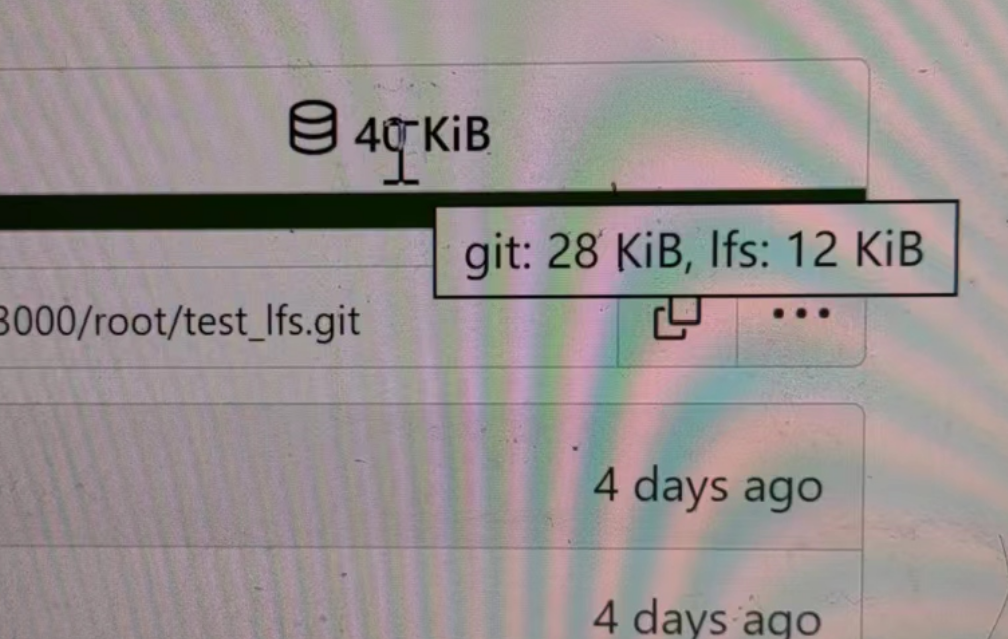
- Return full size in api response.
---------
Signed-off-by: a1012112796 <1012112796@qq.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: DmitryFrolovTri <23313323+DmitryFrolovTri@users.noreply.github.com>
Co-authored-by: Giteabot <teabot@gitea.io>
### Summary
Extend the template variable substitution to replace file paths. This
can be helpful for setting up log files & directories that should match
the repository name.
### PR Changes
- Move files matching glob pattern when setting up repos from template
- For security, added ~escaping~ sanitization for cross-platform support
and to prevent directory traversal (thanks @silverwind for the
reference)
- Added unit testing for escaping function
- Fixed the integration tests for repo template generation by passing
the repo_template_id
- Updated the integration testfiles to add some variable substitution &
assert the outputs
I had to fix the existing repo template integration test and extend it
to add a check for variable substitutions.
Example:
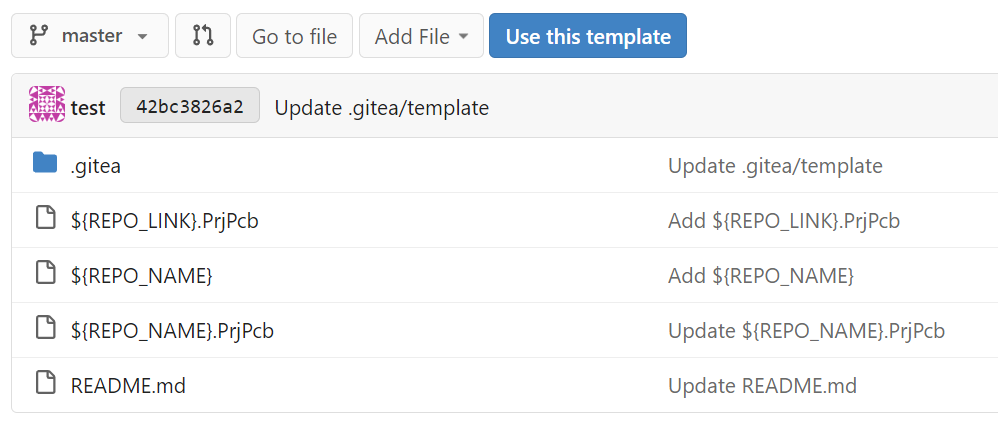
The INI package has many bugs and quirks, and in fact it is
unmaintained.
This PR is the first step for the INI package refactoring:
* Use Gitea's "config_provider" to provide INI access
* Deprecate the INI package by golangci.yml rule
This PR replaces all string refName as a type `git.RefName` to make the
code more maintainable.
Fix #15367
Replaces #23070
It also fixed a bug that tags are not sync because `git remote --prune
origin` will not remove local tags if remote removed.
We in fact should use `git fetch --prune --tags origin` but not `git
remote update origin` to do the sync.
Some answer from ChatGPT as ref.
> If the git fetch --prune --tags command is not working as expected,
there could be a few reasons why. Here are a few things to check:
>
>Make sure that you have the latest version of Git installed on your
system. You can check the version by running git --version in your
terminal. If you have an outdated version, try updating Git and see if
that resolves the issue.
>
>Check that your Git repository is properly configured to track the
remote repository's tags. You can check this by running git config
--get-all remote.origin.fetch and verifying that it includes
+refs/tags/*:refs/tags/*. If it does not, you can add it by running git
config --add remote.origin.fetch "+refs/tags/*:refs/tags/*".
>
>Verify that the tags you are trying to prune actually exist on the
remote repository. You can do this by running git ls-remote --tags
origin to list all the tags on the remote repository.
>
>Check if any local tags have been created that match the names of tags
on the remote repository. If so, these local tags may be preventing the
git fetch --prune --tags command from working properly. You can delete
local tags using the git tag -d command.
---------
Co-authored-by: delvh <dev.lh@web.de>
Replace #22117. Implement it in a more maintainable way.
Some licenses have placeholders e.g. the BSD licenses start with this
line:
```
Copyright (c) <year> <owner>.
```
This PR replaces the placeholders with the correct value when initialize
a new repo.
### FAQ
- Why not use a regex?
It will be a pretty complicated regex which could be hard to maintain.
- There're still missing placeholders.
There are over 500 licenses, it's impossible for anyone to inspect all
of them alone. Please help to add them if you find any, and it is also
OK to leave them for the future.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
There was only one `IsRepositoryExist` function, it did: `has && isDir`
However it's not right, and it would cause 500 error when creating a new
repository if the dir exists.
Then, it was changed to `has || isDir`, it is still incorrect, it
affects the "adopt repo" logic.
To make the logic clear:
* IsRepositoryModelOrDirExist
* IsRepositoryModelExist
The idea is to use a Layered Asset File-system (modules/assetfs/layered.go)
For example: when there are 2 layers: "custom", "builtin", when access
to asset "my/page.tmpl", the Layered Asset File-system will first try to
use "custom" assets, if not found, then use "builtin" assets.
This approach will hugely simplify a lot of code, make them testable.
Other changes:
* Simplify the AssetsHandlerFunc code
* Simplify the `gitea embedded` sub-command code
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
When the base repository contains multiple branches with the same
commits as the base branch, pull requests can show a long list of
commits already in the base branch as having been added.
What this is supposed to do is exclude commits already in the base
branch. But the mechansim to do so assumed a commit only exists in a
single branch. Now use `git rev-list A B --not branchName` instead of
filtering commits afterwards.
The logic to detect if there was a force push also was wrong for
multiple branches. If the old commit existed in any branch in the base
repository it would assume there was no force push. Instead check if the
old commit is an ancestor of the new commit.
Avoid maintaining two copies of code, some functions can be used with
both `bindata` and `no bindata`.
And removed `GetRepoInitFile`, it's useless now.
`Readme`/`Gitignore`/`License`/`Labels` will clean the name and use
custom files when available.
Extract from #11669 and enhancement to #22585 to support exclusive
scoped labels in label templates
* Move label template functionality to label module
* Fix handling of color codes
* Add Advanced label template
Partially fix #23050
After #22294 merged, it always has a warning log like `cannot get
context cache` when starting up. This should not affect any real life
but it's annoying. This PR will fix the problem. That means when
starting up, getting the system settings will not try from the cache but
will read from the database directly.
---------
Co-authored-by: Lauris BH <lauris@nix.lv>
Close #23027
`git commit` message option _only_ supports 4 formats (well, only ....):
* `"commit", "-m", msg`
* `"commit", "-m{msg}"` (no space)
* `"commit", "--message", msg`
* `"commit", "--message={msg}"`
The long format with `=` is the best choice, and it's documented in `man
git-commit`:
`-m <msg>, --message=<msg> ...`
ps: I would suggest always use long format option for git command, as
much as possible.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
Fixes #19555
Test-Instructions:
https://github.com/go-gitea/gitea/pull/21441#issuecomment-1419438000
This PR implements the mapping of user groups provided by OIDC providers
to orgs teams in Gitea. The main part is a refactoring of the existing
LDAP code to make it usable from different providers.
Refactorings:
- Moved the router auth code from module to service because of import
cycles
- Changed some model methods to take a `Context` parameter
- Moved the mapping code from LDAP to a common location
I've tested it with Keycloak but other providers should work too. The
JSON mapping format is the same as for LDAP.
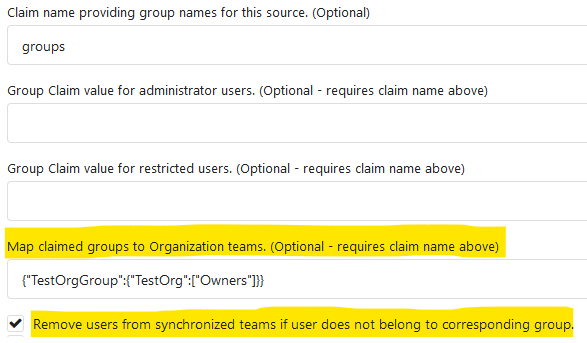
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Most of the time forks are used for contributing code only, so not
having
issues, projects, release and packages is a better default for such
cases.
They can still be enabled in the settings.
A new option `DEFAULT_FORK_REPO_UNITS` is added to configure the default
units on forks.
Also add missing `repo.packages` unit to documentation.
code by: @brechtvl
## ⚠️ BREAKING ⚠️
When forking a repository, the fork will now have issues, projects,
releases, packages and wiki disabled. These can be enabled in the
repository settings afterwards. To change back to the previous default
behavior, configure `DEFAULT_FORK_REPO_UNITS` to be the same value as
`DEFAULT_REPO_UNITS`.
Co-authored-by: Brecht Van Lommel <brecht@blender.org>
This PR follows #21535 (and replace #22592)
## Review without space diff
https://github.com/go-gitea/gitea/pull/22678/files?diff=split&w=1
## Purpose of this PR
1. Make git module command completely safe (risky user inputs won't be
passed as argument option anymore)
2. Avoid low-level mistakes like
https://github.com/go-gitea/gitea/pull/22098#discussion_r1045234918
3. Remove deprecated and dirty `CmdArgCheck` function, hide the `CmdArg`
type
4. Simplify code when using git command
## The main idea of this PR
* Move the `git.CmdArg` to the `internal` package, then no other package
except `git` could use it. Then developers could never do
`AddArguments(git.CmdArg(userInput))` any more.
* Introduce `git.ToTrustedCmdArgs`, it's for user-provided and already
trusted arguments. It's only used in a few cases, for example: use git
arguments from config file, help unit test with some arguments.
* Introduce `AddOptionValues` and `AddOptionFormat`, they make code more
clear and simple:
* Before: `AddArguments("-m").AddDynamicArguments(message)`
* After: `AddOptionValues("-m", message)`
* -
* Before: `AddArguments(git.CmdArg(fmt.Sprintf("--author='%s <%s>'",
sig.Name, sig.Email)))`
* After: `AddOptionFormat("--author='%s <%s>'", sig.Name, sig.Email)`
## FAQ
### Why these changes were not done in #21535 ?
#21535 is mainly a search&replace, it did its best to not change too
much logic.
Making the framework better needs a lot of changes, so this separate PR
is needed as the second step.
### The naming of `AddOptionXxx`
According to git's manual, the `--xxx` part is called `option`.
### How can it guarantee that `internal.CmdArg` won't be not misused?
Go's specification guarantees that. Trying to access other package's
internal package causes compilation error.
And, `golangci-lint` also denies the git/internal package. Only the
`git/command.go` can use it carefully.
### There is still a `ToTrustedCmdArgs`, will it still allow developers
to make mistakes and pass untrusted arguments?
Generally speaking, no. Because when using `ToTrustedCmdArgs`, the code
will be very complex (see the changes for examples). Then developers and
reviewers can know that something might be unreasonable.
### Why there was a `CmdArgCheck` and why it's removed?
At the moment of #21535, to reduce unnecessary changes, `CmdArgCheck`
was introduced as a hacky patch. Now, almost all code could be written
as `cmd := NewCommand(); cmd.AddXxx(...)`, then there is no need for
`CmdArgCheck` anymore.
### Why many codes for `signArg == ""` is deleted?
Because in the old code, `signArg` could never be empty string, it's
either `-S[key-id]` or `--no-gpg-sign`. So the `signArg == ""` is just
dead code.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
As suggest by Go developers, use `filepath.WalkDir` instead of
`filepath.Walk` because [*Walk is less efficient than WalkDir,
introduced in Go 1.16, which avoids calling `os.Lstat` on every file or
directory visited](https://pkg.go.dev/path/filepath#Walk).
This proposition address that, in a similar way as
https://github.com/go-gitea/gitea/pull/22392 did.
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Fix #22386
`GetDirectorySize` moved as `getDirectorySize` because it becomes a
special function which should not be put in `util`.
Co-authored-by: Jason Song <i@wolfogre.com>
- Move the file `compare.go` and `slice.go` to `slice.go`.
- Fix `ExistsInSlice`, it's buggy
- It uses `sort.Search`, so it assumes that the input slice is sorted.
- It passes `func(i int) bool { return slice[i] == target })` to
`sort.Search`, that's incorrect, check the doc of `sort.Search`.
- Conbine `IsInt64InSlice(int64, []int64)` and `ExistsInSlice(string,
[]string)` to `SliceContains[T]([]T, T)`.
- Conbine `IsSliceInt64Eq([]int64, []int64)` and `IsEqualSlice([]string,
[]string)` to `SliceSortedEqual[T]([]T, T)`.
- Add `SliceEqual[T]([]T, T)` as a distinction from
`SliceSortedEqual[T]([]T, T)`.
- Redesign `RemoveIDFromList([]int64, int64) ([]int64, bool)` to
`SliceRemoveAll[T]([]T, T) []T`.
- Add `SliceContainsFunc[T]([]T, func(T) bool)` and
`SliceRemoveAllFunc[T]([]T, func(T) bool)` for general use.
- Add comments to explain why not `golang.org/x/exp/slices`.
- Add unit tests.
After #22362, we can feel free to use transactions without
`db.DefaultContext`.
And there are still lots of models using `db.DefaultContext`, I think we
should refactor them carefully and one by one.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}