Backport #27486 by @lunny
Fix #27204
This PR allows `/<username>/<reponame>/attachments/<uuid>` access with
personal access token and also changed attachments API download url to
it so it can be download correctly.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Backport #25097
The API should only return the real Mail of a User, if the caller is
logged in. The check do to this don't work. This PR fixes this. This not
really a security issue, but can lead to Spam.
Co-authored-by: JakobDev <jakobdev@gmx.de>
Co-authored-by: silverwind <me@silverwind.io>
This adds the ability to pin important Issues and Pull Requests. You can
also move pinned Issues around to change their Position. Resolves #2175.
## Screenshots
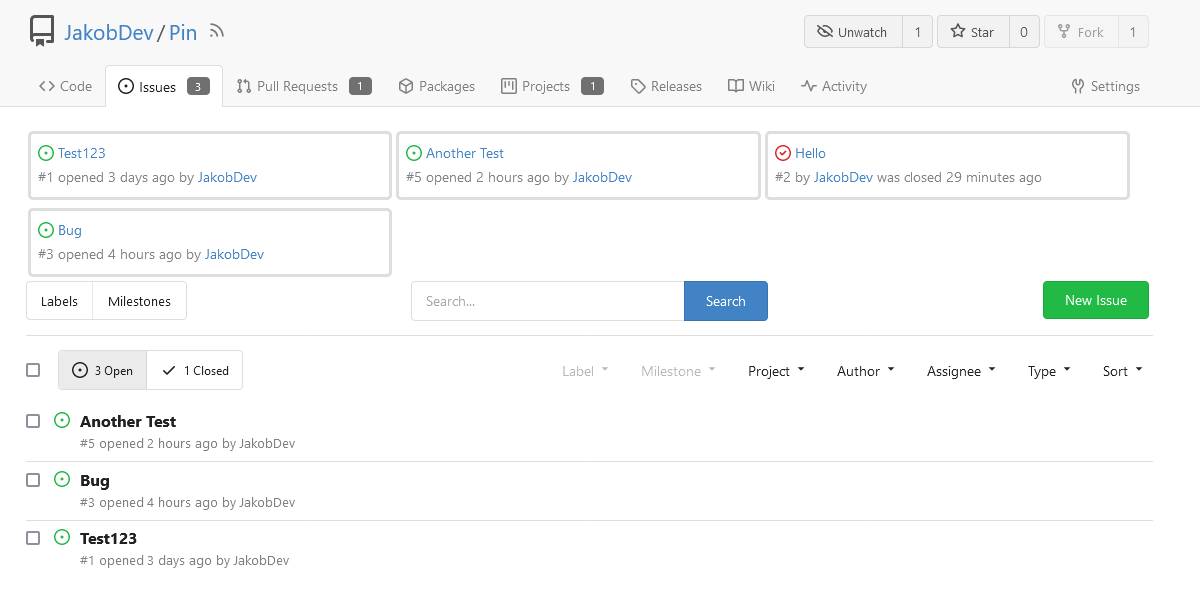
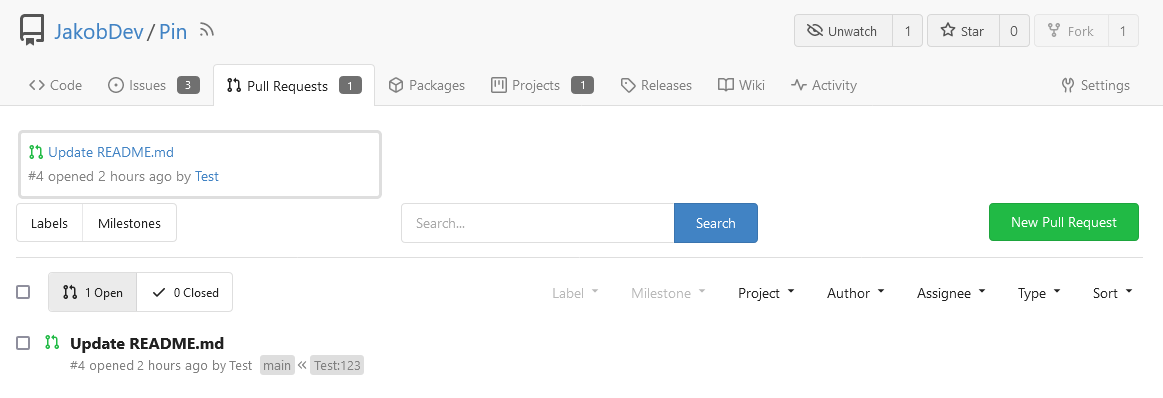
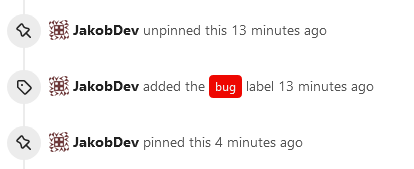
The Design was mostly copied from the Projects Board.
## Implementation
This uses a new `pin_order` Column in the `issue` table. If the value is
set to 0, the Issue is not pinned. If it's set to a bigger value, the
value is the Position. 1 means it's the first pinned Issue, 2 means it's
the second one etc. This is dived into Issues and Pull requests for each
Repo.
## TODO
- [x] You can currently pin as many Issues as you want. Maybe we should
add a Limit, which is configurable. GitHub uses 3, but I prefer 6, as
this is better for bigger Projects, but I'm open for suggestions.
- [x] Pin and Unpin events need to be added to the Issue history.
- [x] Tests
- [x] Migration
**The feature itself is currently fully working, so tester who may find
weird edge cases are very welcome!**
---------
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: Giteabot <teabot@gitea.io>
close https://github.com/go-gitea/gitea/issues/16321
Provided a webhook trigger for requesting someone to review the Pull
Request.
Some modifications have been made to the returned `PullRequestPayload`
based on the GitHub webhook settings, including:
- add a description of the current reviewer object as
`RequestedReviewer` .
- setting the action to either **review_requested** or
**review_request_removed** based on the operation.
- adding the `RequestedReviewers` field to the issues_model.PullRequest.
This field will be loaded into the PullRequest through
`LoadRequestedReviewers()` when `ToAPIPullRequest` is called.
After the Pull Request is merged, I will supplement the relevant
documentation.
The `GetAllCommits` endpoint can be pretty slow, especially in repos
with a lot of commits. The issue is that it spends a lot of time
calculating information that may not be useful/needed by the user.
The `stat` param was previously added in #21337 to address this, by
allowing the user to disable the calculating stats for each commit. But
this has two issues:
1. The name `stat` is rather misleading, because disabling `stat`
disables the Stat **and** Files. This should be separated out into two
different params, because getting a list of affected files is much less
expensive than calculating the stats
2. There's still other costly information provided that the user may not
need, such as `Verification`
This PR, adds two parameters to the endpoint, `files` and `verification`
to allow the user to explicitly disable this information when listing
commits. The default behavior is true.
# ⚠️ Breaking
Many deprecated queue config options are removed (actually, they should
have been removed in 1.18/1.19).
If you see the fatal message when starting Gitea: "Please update your
app.ini to remove deprecated config options", please follow the error
messages to remove these options from your app.ini.
Example:
```
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].ISSUE_INDEXER_QUEUE_TYPE`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [E] Removed queue option: `[indexer].UPDATE_BUFFER_LEN`. Use new options in `[queue.issue_indexer]`
2023/05/06 19:39:22 [F] Please update your app.ini to remove deprecated config options
```
Many options in `[queue]` are are dropped, including:
`WRAP_IF_NECESSARY`, `MAX_ATTEMPTS`, `TIMEOUT`, `WORKERS`,
`BLOCK_TIMEOUT`, `BOOST_TIMEOUT`, `BOOST_WORKERS`, they can be removed
from app.ini.
# The problem
The old queue package has some legacy problems:
* complexity: I doubt few people could tell how it works.
* maintainability: Too many channels and mutex/cond are mixed together,
too many different structs/interfaces depends each other.
* stability: due to the complexity & maintainability, sometimes there
are strange bugs and difficult to debug, and some code doesn't have test
(indeed some code is difficult to test because a lot of things are mixed
together).
* general applicability: although it is called "queue", its behavior is
not a well-known queue.
* scalability: it doesn't seem easy to make it work with a cluster
without breaking its behaviors.
It came from some very old code to "avoid breaking", however, its
technical debt is too heavy now. It's a good time to introduce a better
"queue" package.
# The new queue package
It keeps using old config and concept as much as possible.
* It only contains two major kinds of concepts:
* The "base queue": channel, levelqueue, redis
* They have the same abstraction, the same interface, and they are
tested by the same testing code.
* The "WokerPoolQueue", it uses the "base queue" to provide "worker
pool" function, calls the "handler" to process the data in the base
queue.
* The new code doesn't do "PushBack"
* Think about a queue with many workers, the "PushBack" can't guarantee
the order for re-queued unhandled items, so in new code it just does
"normal push"
* The new code doesn't do "pause/resume"
* The "pause/resume" was designed to handle some handler's failure: eg:
document indexer (elasticsearch) is down
* If a queue is paused for long time, either the producers blocks or the
new items are dropped.
* The new code doesn't do such "pause/resume" trick, it's not a common
queue's behavior and it doesn't help much.
* If there are unhandled items, the "push" function just blocks for a
few seconds and then re-queue them and retry.
* The new code doesn't do "worker booster"
* Gitea's queue's handlers are light functions, the cost is only the
go-routine, so it doesn't make sense to "boost" them.
* The new code only use "max worker number" to limit the concurrent
workers.
* The new "Push" never blocks forever
* Instead of creating more and more blocking goroutines, return an error
is more friendly to the server and to the end user.
There are more details in code comments: eg: the "Flush" problem, the
strange "code.index" hanging problem, the "immediate" queue problem.
Almost ready for review.
TODO:
* [x] add some necessary comments during review
* [x] add some more tests if necessary
* [x] update documents and config options
* [x] test max worker / active worker
* [x] re-run the CI tasks to see whether any test is flaky
* [x] improve the `handleOldLengthConfiguration` to provide more
friendly messages
* [x] fine tune default config values (eg: length?)
## Code coverage:

Close #7570
1. Clearly define the wiki path behaviors, see
`services/wiki/wiki_path.go` and tests
2. Keep compatibility with old contents
3. Allow to use dashes in titles, eg: "2000-01-02 Meeting record"
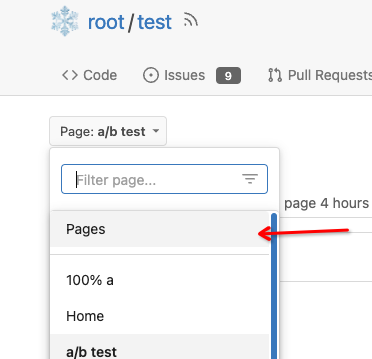
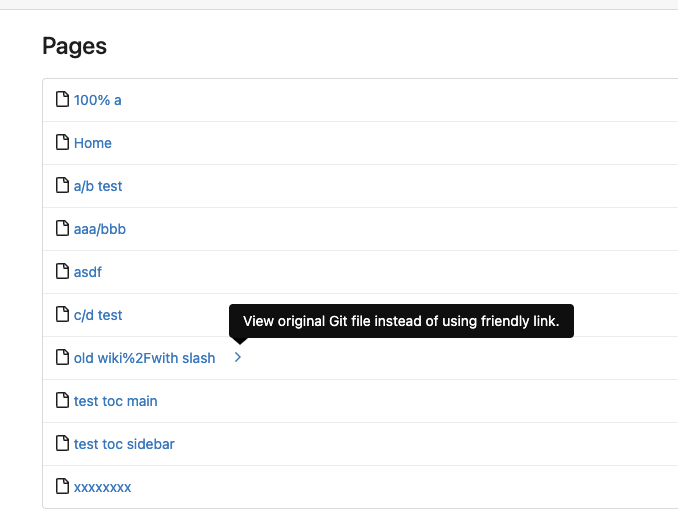
4. Add a "Pages" link in the dropdown, otherwise users can't go to the
Pages page easily.
5. Add a "View original git file" link in the Pages list, even if some
file names are broken, users still have a chance to edit or remove it,
without cloning the wiki repo to local.
6. Fix 500 error when the name contains prefix spaces.
This PR also introduces the ability to support sub-directories, but it
can't be done at the moment due to there are a lot of legacy wiki data,
which use "%2F" in file names.
Co-authored-by: Giteabot <teabot@gitea.io>
Adds API endpoints to manage issue/PR dependencies
* `GET /repos/{owner}/{repo}/issues/{index}/blocks` List issues that are
blocked by this issue
* `POST /repos/{owner}/{repo}/issues/{index}/blocks` Block the issue
given in the body by the issue in path
* `DELETE /repos/{owner}/{repo}/issues/{index}/blocks` Unblock the issue
given in the body by the issue in path
* `GET /repos/{owner}/{repo}/issues/{index}/dependencies` List an
issue's dependencies
* `POST /repos/{owner}/{repo}/issues/{index}/dependencies` Create a new
issue dependencies
* `DELETE /repos/{owner}/{repo}/issues/{index}/dependencies` Remove an
issue dependency
Closes https://github.com/go-gitea/gitea/issues/15393
Closes #22115
Co-authored-by: Andrew Thornton <art27@cantab.net>
Fix: #22990
---
Before, the return value of the api is always false,regrardless of
whether the entry of `sync_on_commit` is true or false.
I have confirmed that the value of `sync_on_commit` dropped into the
database is correct.
So, I think it is enough to make some small changes.
Add a new "exclusive" option per label. This makes it so that when the
label is named `scope/name`, no other label with the same `scope/`
prefix can be set on an issue.
The scope is determined by the last occurence of `/`, so for example
`scope/alpha/name` and `scope/beta/name` are considered to be in
different scopes and can coexist.
Exclusive scopes are not enforced by any database rules, however they
are enforced when editing labels at the models level, automatically
removing any existing labels in the same scope when either attaching a
new label or replacing all labels.
In menus use a circle instead of checkbox to indicate they function as
radio buttons per scope. Issue filtering by label ensures that only a
single scoped label is selected at a time. Clicking with alt key can be
used to remove a scoped label, both when editing individual issues and
batch editing.
Label rendering refactor for consistency and code simplification:
* Labels now consistently have the same shape, emojis and tooltips
everywhere. This includes the label list and label assignment menus.
* In label list, show description below label same as label menus.
* Don't use exactly black/white text colors to look a bit nicer.
* Simplify text color computation. There is no point computing luminance
in linear color space, as this is a perceptual problem and sRGB is
closer to perceptually linear.
* Increase height of label assignment menus to show more labels. Showing
only 3-4 labels at a time leads to a lot of scrolling.
* Render all labels with a new RenderLabel template helper function.
Label creation and editing in multiline modal menu:
* Change label creation to open a modal menu like label editing.
* Change menu layout to place name, description and colors on separate
lines.
* Don't color cancel button red in label editing modal menu.
* Align text to the left in model menu for better readability and
consistent with settings layout elsewhere.
Custom exclusive scoped label rendering:
* Display scoped label prefix and suffix with slightly darker and
lighter background color respectively, and a slanted edge between them
similar to the `/` symbol.
* In menus exclusive labels are grouped with a divider line.
---------
Co-authored-by: Yarden Shoham <hrsi88@gmail.com>
Co-authored-by: Lauris BH <lauris@nix.lv>
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
Add setting to allow edits by maintainers by default, to avoid having to
often ask contributors to enable this.
This also reorganizes the pull request settings UI to improve clarity.
It was unclear which checkbox options were there to control available
merge styles and which merge styles they correspond to.
Now there is a "Merge Styles" label followed by the merge style options
with the same name as in other menus. The remaining checkboxes were
moved to the bottom, ordered rougly by typical order of operations.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
This PR introduce glob match for protected branch name. The separator is
`/` and you can use `*` matching non-separator chars and use `**` across
separator.
It also supports input an exist or non-exist branch name as matching
condition and branch name condition has high priority than glob rule.
Should fix #2529 and #15705
screenshots
<img width="1160" alt="image"
src="https://user-images.githubusercontent.com/81045/205651179-ebb5492a-4ade-4bb4-a13c-965e8c927063.png">
Co-authored-by: zeripath <art27@cantab.net>
After #22362, we can feel free to use transactions without
`db.DefaultContext`.
And there are still lots of models using `db.DefaultContext`, I think we
should refactor them carefully and one by one.
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Previously, there was an `import services/webhooks` inside
`modules/notification/webhook`.
This import was removed (after fighting against many import cycles).
Additionally, `modules/notification/webhook` was moved to
`modules/webhook`,
and a few structs/constants were extracted from `models/webhooks` to
`modules/webhook`.
Co-authored-by: 6543 <6543@obermui.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}