Fix #28157
This PR fix the possible bugs about actions schedule.
## The Changes
- Move `UpdateRepositoryUnit` and `SetRepoDefaultBranch` from models to
service layer
- Remove schedules plan from database and cancel waiting & running
schedules tasks in this repository when actions unit has been disabled
or global disabled.
- Remove schedules plan from database and cancel waiting & running
schedules tasks in this repository when default branch changed.
Introduce the new generic deletion methods
- `func DeleteByID[T any](ctx context.Context, id int64) (int64, error)`
- `func DeleteByIDs[T any](ctx context.Context, ids ...int64) error`
- `func Delete[T any](ctx context.Context, opts FindOptions) (int64,
error)`
So, we no longer need any specific deletion method and can just use
the generic ones instead.
Replacement of #28450
Closes #28450
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
- If a topic has zero repository count, it means that none of the
repositories are using that topic, that would make them 'useless' to
keep. One caveat is that if that topic is going to be used in the
future, it will be added again to the database, but simply with a new
ID.
Refs: https://codeberg.org/forgejo/forgejo/pulls/1964
Co-authored-by: Gusted <postmaster@gusted.xyz>
- Remove `ObjectFormatID`
- Remove function `ObjectFormatFromID`.
- Use `Sha1ObjectFormat` directly but not a pointer because it's an
empty struct.
- Store `ObjectFormatName` in `repository` struct
Refactor Hash interfaces and centralize hash function. This will allow
easier introduction of different hash function later on.
This forms the "no-op" part of the SHA256 enablement patch.
- Currently the repository description uses the same sanitizer as a
normal markdown document. This means that element such as heading and
images are allowed and can be abused.
- Create a minimal restricted sanitizer for the repository description,
which only allows what the postprocessor currently allows, which are
links and emojis.
- Added unit testing.
- Resolves https://codeberg.org/forgejo/forgejo/issues/1202
- Resolves https://codeberg.org/Codeberg/Community/issues/1122
(cherry picked from commit 631c87cc23)
Co-authored-by: Gusted <postmaster@gusted.xyz>
Part of #27065
This PR touches functions used in templates. As templates are not static
typed, errors are harder to find, but I hope I catch it all. I think
some tests from other persons do not hurt.
This PR removed `unittest.MainTest` the second parameter
`TestOptions.GiteaRoot`. Now it detects the root directory by current
working directory.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
This PR adds a new field `RemoteAddress` to both mirror types which
contains the sanitized remote address for easier (database) access to
that information. Will be used in the audit PR if merged.
Part of #27065
This reduces the usage of `db.DefaultContext`. I think I've got enough
files for the first PR. When this is merged, I will continue working on
this.
Considering how many files this PR affect, I hope it won't take to long
to merge, so I don't end up in the merge conflict hell.
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Fix #26723
Add `ChangeDefaultBranch` to the `notifier` interface and implement it
in `indexerNotifier`. So when changing the default branch,
`indexerNotifier` sends a message to the `indexer queue` to update the
index.
---------
Co-authored-by: techknowlogick <matti@mdranta.net>
- Resolves https://codeberg.org/forgejo/forgejo/issues/580
- Return a `upload_field` to any release API response, which points to
the API URL for uploading new assets.
- Adds unit test.
- Adds integration testing to verify URL is returned correctly and that
upload endpoint actually works
---------
Co-authored-by: Gusted <postmaster@gusted.xyz>
This PR has multiple parts, and I didn't split them because
it's not easy to test them separately since they are all about the
dashboard page for issues.
1. Support counting issues via indexer to fix #26361
2. Fix repo selection so it also fixes #26653
3. Keep keywords in filter links.
The first two are regressions of #26012.
After:
https://github.com/go-gitea/gitea/assets/9418365/71dfea7e-d9e2-42b6-851a-cc081435c946
Thanks to @CaiCandong for helping with some tests.
This PR will display a pull request creation hint on the repository home
page when there are newly created branches with no pull request. Only
the recent 6 hours and 2 updated branches will be displayed.
Inspired by #14003
Replace #14003
Resolves #311
Resolves #13196
Resolves #23743
co-authored by @kolaente
Add a few extra test cases and test functions for the collaboration
model to get everything covered by tests (except for error handling, as
we cannot suddenly mock errors from the database).
Co-authored-by: Gusted <postmaster@gusted.xyz>
Reviewed-on: https://codeberg.org/forgejo/forgejo/pulls/825
Co-authored-by: Gusted <gusted@noreply.codeberg.org>
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: Giteabot <teabot@gitea.io>
releated to #21820
- Split `Size` in repository table as two new colunms, one is `GitSize`
for git size, the other is `LFSSize` for lfs data. still store full size
in `Size` colunm.
- Show full size on ui, but show each of them by a `title`; example:
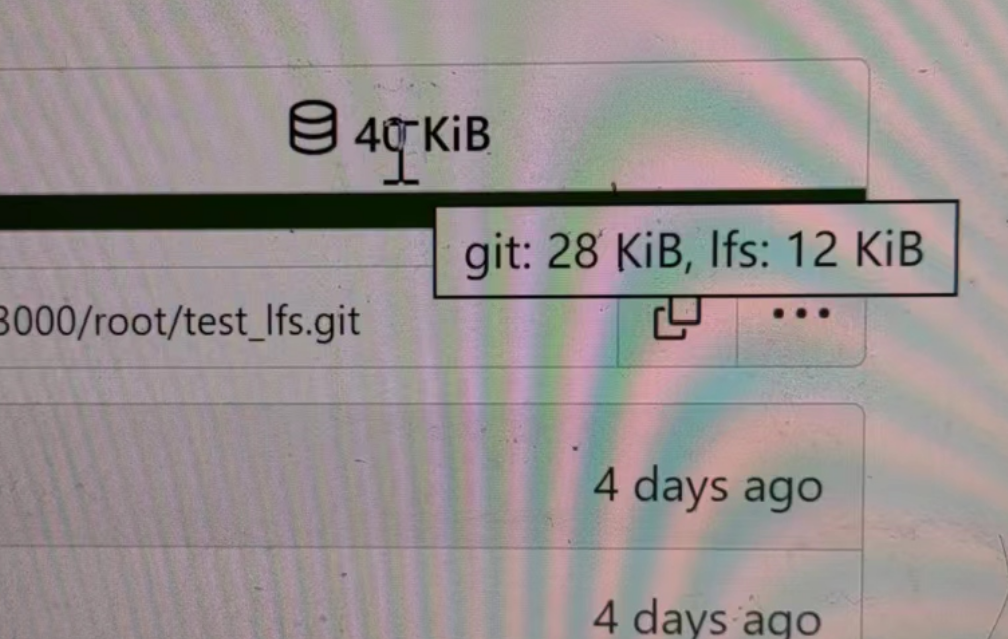
- Return full size in api response.
---------
Signed-off-by: a1012112796 <1012112796@qq.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: DmitryFrolovTri <23313323+DmitryFrolovTri@users.noreply.github.com>
Co-authored-by: Giteabot <teabot@gitea.io>
## ⚠️ Breaking
The `log.<mode>.<logger>` style config has been dropped. If you used it,
please check the new config manual & app.example.ini to make your
instance output logs as expected.
Although many legacy options still work, it's encouraged to upgrade to
the new options.
The SMTP logger is deleted because SMTP is not suitable to collect logs.
If you have manually configured Gitea log options, please confirm the
logger system works as expected after upgrading.
## Description
Close #12082 and maybe more log-related issues, resolve some related
FIXMEs in old code (which seems unfixable before)
Just like rewriting queue #24505 : make code maintainable, clear legacy
bugs, and add the ability to support more writers (eg: JSON, structured
log)
There is a new document (with examples): `logging-config.en-us.md`
This PR is safer than the queue rewriting, because it's just for
logging, it won't break other logic.
## The old problems
The logging system is quite old and difficult to maintain:
* Unclear concepts: Logger, NamedLogger, MultiChannelledLogger,
SubLogger, EventLogger, WriterLogger etc
* Some code is diffuclt to konw whether it is right:
`log.DelNamedLogger("console")` vs `log.DelNamedLogger(log.DEFAULT)` vs
`log.DelLogger("console")`
* The old system heavily depends on ini config system, it's difficult to
create new logger for different purpose, and it's very fragile.
* The "color" trick is difficult to use and read, many colors are
unnecessary, and in the future structured log could help
* It's difficult to add other log formats, eg: JSON format
* The log outputer doesn't have full control of its goroutine, it's
difficult to make outputer have advanced behaviors
* The logs could be lost in some cases: eg: no Fatal error when using
CLI.
* Config options are passed by JSON, which is quite fragile.
* INI package makes the KEY in `[log]` section visible in `[log.sub1]`
and `[log.sub1.subA]`, this behavior is quite fragile and would cause
more unclear problems, and there is no strong requirement to support
`log.<mode>.<logger>` syntax.
## The new design
See `logger.go` for documents.
## Screenshot
<details>



</details>
## TODO
* [x] add some new tests
* [x] fix some tests
* [x] test some sub-commands (manually ....)
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Giteabot <teabot@gitea.io>
This PR is a refactor at the beginning. And now it did 4 things.
- [x] Move renaming organizaiton and user logics into services layer and
merged as one function
- [x] Support rename a user capitalization only. For example, rename the
user from `Lunny` to `lunny`. We just need to change one table `user`
and others should not be touched.
- [x] Before this PR, some renaming were missed like `agit`
- [x] Fix bug the API reutrned from `http.StatusNoContent` to `http.StatusOK`
The topics are saved in the `repo_topic` table.
They are also saved directly in the `repository` table.
Before this PR, only `AddTopic` and `SaveTopics` made sure the `topics`
field in the `repository` table was synced with the `repo_topic` table.
This PR makes sure `GenerateTopics` and `DeleteTopic`
also sync the `topics` in the repository table.
`RemoveTopicsFromRepo` doesn't need to sync the data
as it is only used to delete a repository.
Fixes #24820
Fixes #24145
To solve the bug, I added a "computed" `TargetBehind` field to the
`Release` model, which indicates the target branch of a release.
This is particularly useful if the target branch was deleted in the
meantime (or is empty).
I also did a micro-optimization in `calReleaseNumCommitsBehind`. Instead
of checking that a branch exists and then call `GetBranchCommit`, I
immediately call `GetBranchCommit` and handle the `git.ErrNotExist`
error.
This optimization is covered by the added unit test.
The "modules/context.go" is too large to maintain.
This PR splits it to separate files, eg: context_request.go,
context_response.go, context_serve.go
This PR will help:
1. The future refactoring for Gitea's web context (eg: simplify the context)
2. Introduce proper "range request" support
3. Introduce context function
This PR only moves code, doesn't change any logic.
There was only one `IsRepositoryExist` function, it did: `has && isDir`
However it's not right, and it would cause 500 error when creating a new
repository if the dir exists.
Then, it was changed to `has || isDir`, it is still incorrect, it
affects the "adopt repo" logic.
To make the logic clear:
* IsRepositoryModelOrDirExist
* IsRepositoryModelExist
As promised in #23817, I have this made a PR to make Release Download
URLs predictable. It currently follows the schema
`<repo>/releases/download/<tag>/<filename>`. this already works, but it
is nowhere shown in the UI or the API. The Problem is, that it is
currently possible to have multiple files with the same name (why do we
even allow this) for a release. I had written some Code to check, if a
Release has 2 or more files with the same Name. If yes, it uses the old
`attachments/<uuid>` URlL if no it uses the new fancy URL.
I had also changed `<repo>/releases/download/<tag>/<filename>` to
directly serve the File instead of redirecting, so people who who use
automatic update checker don't end up with the `attachments/<uuid>` URL.
Fixes #10919
---------
Co-authored-by: a1012112796 <1012112796@qq.com>
Right now the authors search dropdown might take a long time to load if
amount of authors is huge.
Example: (In the video below, there are about 10000 authors, and it
takes about 10 seconds to open the author dropdown)
https://user-images.githubusercontent.com/17645053/229422229-98aa9656-3439-4f8c-9f4e-83bd8e2a2557.mov
Possible improvements can be made, which will take 2 steps (Thanks to
@wolfogre for advice):
Step 1:
Backend: Add a new api, which returns a limit of 30 posters with matched
prefix.
Frontend: Change the search behavior from frontend search(fomantic
search) to backend search(when input is changed, send a request to get
authors matching the current search prefix)
Step 2:
Backend: Optimize the api in step 1 using indexer to support fuzzy
search.
This PR is implements the first step. The main changes:
1. Added api: `GET /{type:issues|pulls}/posters` , which return a limit
of 30 users with matched prefix (prefix sent as query). If
`DEFAULT_SHOW_FULL_NAME` in `custom/conf/app.ini` is set to true, will
also include fullnames fuzzy search.
2. Added a tooltip saying "Shows a maximum of 30 users" to the author
search dropdown
3. Change the search behavior from frontend search to backend search
After:
https://user-images.githubusercontent.com/17645053/229430960-f88fafd8-fd5d-4f84-9df2-2677539d5d08.mov
Fixes: https://github.com/go-gitea/gitea/issues/22586
---------
Co-authored-by: wxiaoguang <wxiaoguang@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
This PR fixes the tags sort issue mentioned in #23432
The tags on dropdown shoud be sorted in descending order of time but are
not. Because when getting tags, it execeutes `git tag sort
--sort=-taggerdate`. Git supports two types of tags: lightweight and
annotated, and `git tag sort --sort=-taggerdate` dosen't work with
lightweight tags, which will not give correct result. This PR add
`GetTagNamesByRepoID ` to get tags from the database so the tags are
sorted.
Also adapt this change to the droplist when comparing branches.
Dropdown places:
<img width="369" alt="截屏2023-03-15 14 25 39"
src="https://user-images.githubusercontent.com/17645053/225224506-65a72e50-4c11-41d7-8187-a7e9c7dab2cb.png">
<img width="675" alt="截屏2023-03-15 14 25 27"
src="https://user-images.githubusercontent.com/17645053/225224526-65ce8008-340c-43f6-aa65-b6bd9e1a1bf1.png">
Replace #23350.
Refactor `setting.Database.UseMySQL` to
`setting.Database.Type.IsMySQL()`.
To avoid mismatching between `Type` and `UseXXX`.
This refactor can fix the bug mentioned in #23350, so it should be
backported.
To avoid duplicated load of the same data in an HTTP request, we can set
a context cache to do that. i.e. Some pages may load a user from a
database with the same id in different areas on the same page. But the
code is hidden in two different deep logic. How should we share the
user? As a result of this PR, now if both entry functions accept
`context.Context` as the first parameter and we just need to refactor
`GetUserByID` to reuse the user from the context cache. Then it will not
be loaded twice on an HTTP request.
But of course, sometimes we would like to reload an object from the
database, that's why `RemoveContextData` is also exposed.
The core context cache is here. It defines a new context
```go
type cacheContext struct {
ctx context.Context
data map[any]map[any]any
lock sync.RWMutex
}
var cacheContextKey = struct{}{}
func WithCacheContext(ctx context.Context) context.Context {
return context.WithValue(ctx, cacheContextKey, &cacheContext{
ctx: ctx,
data: make(map[any]map[any]any),
})
}
```
Then you can use the below 4 methods to read/write/del the data within
the same context.
```go
func GetContextData(ctx context.Context, tp, key any) any
func SetContextData(ctx context.Context, tp, key, value any)
func RemoveContextData(ctx context.Context, tp, key any)
func GetWithContextCache[T any](ctx context.Context, cacheGroupKey string, cacheTargetID any, f func() (T, error)) (T, error)
```
Then let's take a look at how `system.GetString` implement it.
```go
func GetSetting(ctx context.Context, key string) (string, error) {
return cache.GetWithContextCache(ctx, contextCacheKey, key, func() (string, error) {
return cache.GetString(genSettingCacheKey(key), func() (string, error) {
res, err := GetSettingNoCache(ctx, key)
if err != nil {
return "", err
}
return res.SettingValue, nil
})
})
}
```
First, it will check if context data include the setting object with the
key. If not, it will query from the global cache which may be memory or
a Redis cache. If not, it will get the object from the database. In the
end, if the object gets from the global cache or database, it will be
set into the context cache.
An object stored in the context cache will only be destroyed after the
context disappeared.
Add setting to allow edits by maintainers by default, to avoid having to
often ask contributors to enable this.
This also reorganizes the pull request settings UI to improve clarity.
It was unclear which checkbox options were there to control available
merge styles and which merge styles they correspond to.
Now there is a "Merge Styles" label followed by the merge style options
with the same name as in other menus. The remaining checkboxes were
moved to the bottom, ordered rougly by typical order of operations.
---------
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Original Issue: https://github.com/go-gitea/gitea/issues/22102
This addition would be a big benefit for design and art teams using the
issue tracking.
The preview will be the latest "image type" attachments on an issue-
simple, and allows for automatic updates of the cover image as issue
progress is made!
This would make Gitea competitive with Trello... wouldn't it be amazing
to say goodbye to Atlassian products? Ha.
First image is the most recent, the SQL will fetch up to 5 latest images
(URL string).
All images supported by browsers plus upcoming formats: *.avif *.bmp
*.gif *.jpg *.jpeg *.jxl *.png *.svg *.webp
The CSS will try to center-align images until it cannot, then it will
left align with overflow hidden. Single images get to be slightly
larger!
Tested so far on: Chrome, Firefox, Android Chrome, Android Firefox.
Current revision with light and dark themes:
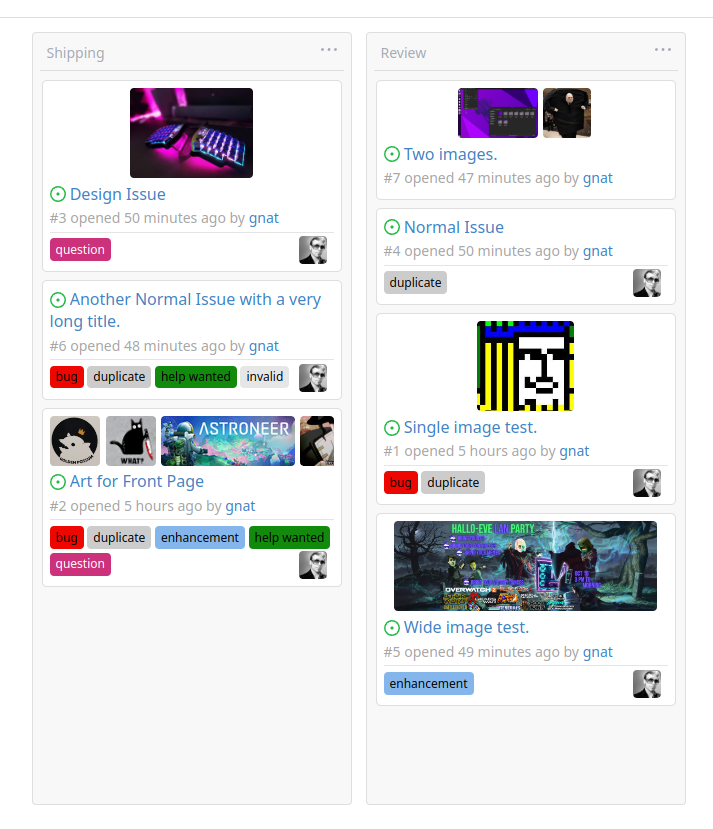
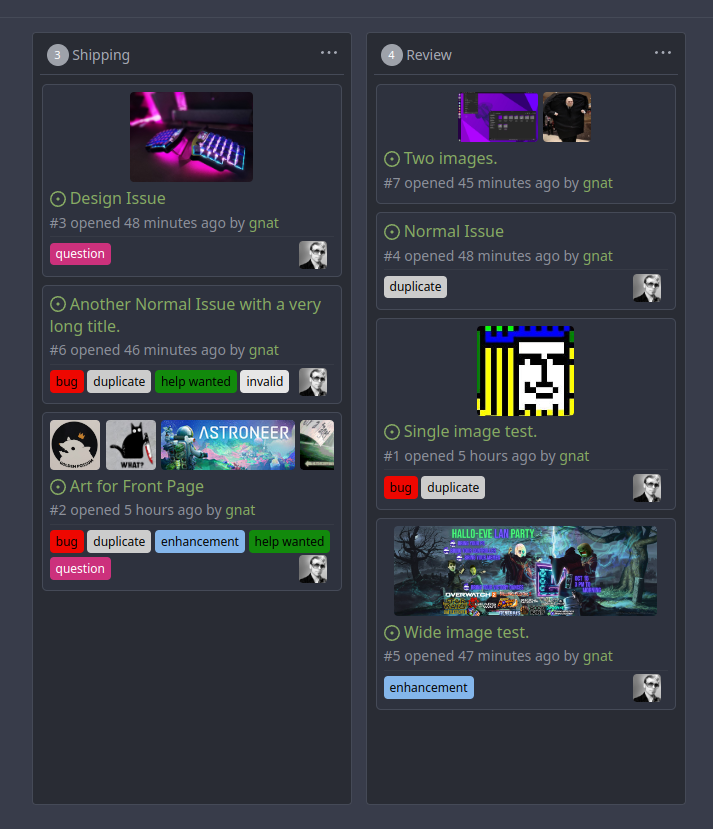
---------
Co-authored-by: Jason Song <i@wolfogre.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: delvh <dev.lh@web.de>
In Go code, HTMLURL should be only used for external systems, like
API/webhook/mail/notification, etc.
If a URL is used by `Redirect` or rendered in a template, it should be a
relative URL (aka `Link()` in Gitea)
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
partially fix #19345
This PR add some `Link` methods for different objects. The `Link`
methods are not different from `HTMLURL`, they are lack of the absolute
URL. And most of UI `HTMLURL` have been replaced to `Link` so that users
can visit them from a different domain or IP.
This PR also introduces a new javascript configuration
`window.config.reqAppUrl` which is different from `appUrl` which is
still an absolute url but the domain has been replaced to the current
requested domain.
Every user can already disable the filter manually, so the explicit
setting is absolutely useless and only complicates the logic.
Previously, there was also unexpected behavior when multiple query
parameters were present.
---------
Co-authored-by: zeripath <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Fix #21994.
And fix #19470.
While generating new repo from a template, it does something like
"commit to git repo, re-fetch repo model from DB, and update default
branch if it's empty".
19d5b2f922/modules/repository/generate.go (L241-L253)
Unfortunately, when load repo from DB, the default branch will be set to
`setting.Repository.DefaultBranch` if it's empty:
19d5b2f922/models/repo/repo.go (L228-L233)
I believe it's a very old temporary patch but has been kept for many
years, see:
[2d2d85bb](https://github.com/go-gitea/gitea/commit/2d2d85bb#diff-1851799b06733db4df3ec74385c1e8850ee5aedee70b8b55366910d22725eea8)
I know it's a risk to delete it, may lead to potential behavioral
changes, but we cannot keep the outdated `FIXME` forever. On the other
hand, an empty `DefaultBranch` does make sense: an empty repo doesn't
have one conceptually (actually, Gitea will still set it to
`setting.Repository.DefaultBranch` to make it safer).
There is a mistake in the code for SearchRepositoryCondition where it
tests topics as a string. This is incorrect for postgres where topics is
cast and stored as json. topics needs to be cast to text for this to
work. (For some reason JSON_ARRAY_LENGTH does not work, so I have taken
the simplest solution of casting to text and doing a string comparison.)
Ref https://github.com/go-gitea/gitea/pull/21962#issuecomment-1379584057
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: delvh <dev.lh@web.de>
Fix #22386
`GetDirectorySize` moved as `getDirectorySize` because it becomes a
special function which should not be put in `util`.
Co-authored-by: Jason Song <i@wolfogre.com>
Fix #22023
I've changed how the percentages for the language statistics are rounded
because they did not always add up to 100%
Now it's done with the largest remainder method, which makes sure that
total is 100%
Co-authored-by: Lauris BH <lauris@nix.lv>
Change all license headers to comply with REUSE specification.
Fix #16132
Co-authored-by: flynnnnnnnnnn <flynnnnnnnnnn@github>
Co-authored-by: John Olheiser <john.olheiser@gmail.com>
This PR adds a context parameter to a bunch of methods. Some helper
`xxxCtx()` methods got replaced with the normal name now.
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
The doctor check `storages` currently only checks the attachment
storage. This PR adds some basic garbage collection functionality for
the other types of storage.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Fix #19513
This PR introduce a new db method `InTransaction(context.Context)`,
and also builtin check on `db.TxContext` and `db.WithTx`.
There is also a new method `db.AutoTx` has been introduced but could be used by other PRs.
`WithTx` will always open a new transaction, if a transaction exist in context, return an error.
`AutoTx` will try to open a new transaction if no transaction exist in context.
That means it will always enter a transaction if there is no error.
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: 6543 <6543@obermui.de>
A lot of our code is repeatedly testing if individual errors are
specific types of Not Exist errors. This is repetitative and unnecesary.
`Unwrap() error` provides a common way of labelling an error as a
NotExist error and we can/should use this.
This PR has chosen to use the common `io/fs` errors e.g.
`fs.ErrNotExist` for our errors. This is in some ways not completely
correct as these are not filesystem errors but it seems like a
reasonable thing to do and would allow us to simplify a lot of our code
to `errors.Is(err, fs.ErrNotExist)` instead of
`package.IsErr...NotExist(err)`
I am open to suggestions to use a different base error - perhaps
`models/db.ErrNotExist` if that would be felt to be better.
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: delvh <dev.lh@web.de>
* fix hard-coded timeout and error panic in API archive download endpoint
This commit updates the `GET /api/v1/repos/{owner}/{repo}/archive/{archive}`
endpoint which prior to this PR had a couple of issues.
1. The endpoint had a hard-coded 20s timeout for the archiver to complete after
which a 500 (Internal Server Error) was returned to client. For a scripted
API client there was no clear way of telling that the operation timed out and
that it should retry.
2. Whenever the timeout _did occur_, the code used to panic. This was caused by
the API endpoint "delegating" to the same call path as the web, which uses a
slightly different way of reporting errors (HTML rather than JSON for
example).
More specifically, `api/v1/repo/file.go#GetArchive` just called through to
`web/repo/repo.go#Download`, which expects the `Context` to have a `Render`
field set, but which is `nil` for API calls. Hence, a `nil` pointer error.
The code addresses (1) by dropping the hard-coded timeout. Instead, any
timeout/cancelation on the incoming `Context` is used.
The code addresses (2) by updating the API endpoint to use a separate call path
for the API-triggered archive download. This avoids producing HTML-errors on
errors (it now produces JSON errors).
Signed-off-by: Peter Gardfjäll <peter.gardfjall.work@gmail.com>
Adds a new option to only show relevant repo's on the explore page, for bigger Gitea instances like Codeberg this is a nice option to enable to make the explore page more populated with unique and "high" quality repo's. A note is shown that the results are filtered and have the possibility to see the unfiltered results.
Co-authored-by: vednoc <vednoc@protonmail.com>
Co-authored-by: delvh <dev.lh@web.de>
Co-authored-by: 6543 <6543@obermui.de>
Whilst looking at #20840 I noticed that the Mirrors data doesn't appear
to be being used therefore we can remove this and in fact none of the
related code is used elsewhere so it can also be removed.
Related #20840
Related #20804
Signed-off-by: Andrew Thornton <art27@cantab.net>
Signed-off-by: Andrew Thornton <art27@cantab.net>
In MirrorRepositoryList.loadAttributes there is some code to load the Mirror entries
from the database. This assumes that every Repository which has IsMirror set has
a Mirror associated in the DB. This association is incorrect in the case of
Mirror repository under creation when there is no Mirror entry in the DB until
completion.
Unfortunately LoadAttributes makes this incorrect assumption and presumes that a
Mirror will always be loaded. This then causes a panic.
This PR simply double checks if there a Mirror before attempting to link back to
its Repo. Unfortunately it should be expected that there may be other cases where
this incorrect assumption causes further problems.
Fix #20804
Signed-off-by: Andrew Thornton <art27@cantab.net>
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
- Add a new push mirror to specific repository
- Sync now ( send all the changes to the configured push mirrors )
- Get list of all push mirrors of a repository
- Get a push mirror by ID
- Delete push mirror by ID
Signed-off-by: Mohamed Sekour <mohamed.sekour@exfo.com>
Signed-off-by: Andrew Thornton <art27@cantab.net>
Co-authored-by: zeripath <art27@cantab.net>
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}
{kind=link}