(cherry picked from commit 2f95143000)
(cherry picked from commit 42f2f8731e)
[CLI] implement forgejo-cli actions register (squash) no private
Do not go through the private API, directly modify the database
(cherry picked from commit 1ba7c0d39d)
The `FileBlame` function looks strange, it has `revision` as argument
but doesn't use it.
Since the function never be used, I think we could just remove it.
If anyone thinks it should be kept, please help fix `revision`.
Co-authored-by: Giteabot <teabot@gitea.io>
Replace #25580
Fix #19453
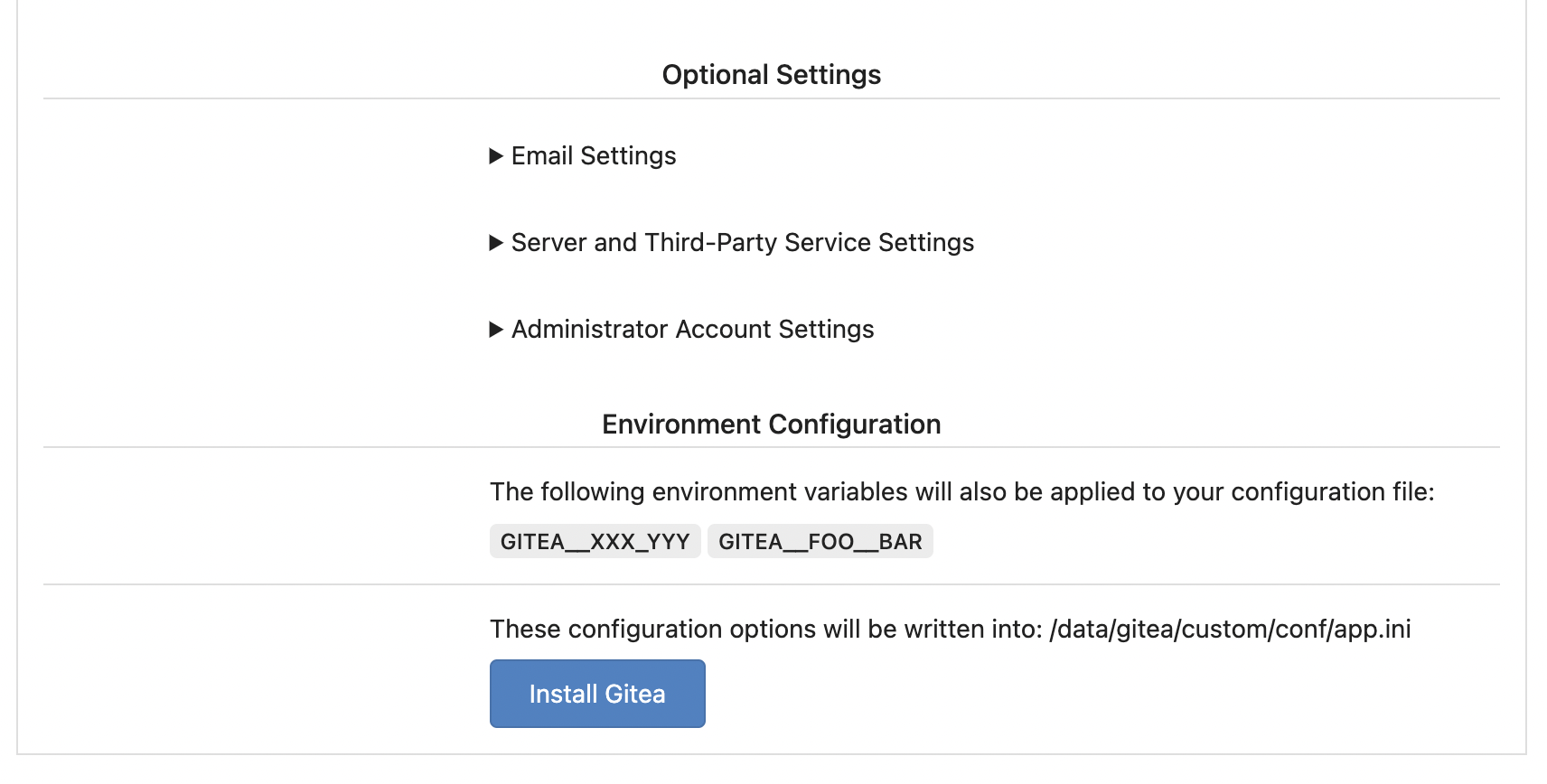
The problem was: when users set "GITEA__XXX__YYY" , the "install page"
doesn't respect it.
So, to make the result consistent and avoid surprising end users, now
the "install page" also writes the environment variables to the config
file.
And, to make things clear, there are enough messages on the UI to tell
users what will happen.
There are some necessary/related changes to `environment-to-ini.go`:
* The "--clear" flag is removed and it was incorrectly written there.
The "clear" operation should be done if INSTALL_LOCK=true
* The "--prefix" flag is removed because it's never used, never
documented and it only causes inconsistent behavior.
Fixes (?) #25538
Fixes https://codeberg.org/forgejo/forgejo/issues/972
Regression #23879#23879 introduced a change which prevents read access to packages if a
user is not a member of an organization.
That PR also contained a change which disallows package access if the
team unit is configured with "no access" for packages. I don't think
this change makes sense (at the moment). It may be relevant for private
orgs. But for public or limited orgs that's useless because an
unauthorized user would have more access rights than the team member.
This PR restores the old behaviour "If a user has read access for an
owner, they can read packages".
---------
Co-authored-by: Giteabot <teabot@gitea.io>
To mock a handler:
```go
web.RouteMock(web.MockAfterMiddlewares, func(ctx *context.Context) {
// ...
})
defer web.RouteMockReset()
```
It helps:
* Test the middleware's behavior (assert the ctx.Data, etc)
* Mock the middleware's behavior (prepare some context data for handler)
* Mock the handler's response for some test cases, especially for some
integration tests and e2e tests.
Follow #25229
At present, when the trigger event is `pull_request_target`, the `ref`
and `sha` of `ActionRun` are set according to the base branch of the
pull request. This makes it impossible for us to find the head branch of
the `ActionRun` directly. In this PR, the `ref` and `sha` will always be
set to the head branch and they will be changed to the base branch when
generating the task context.
A couple of notes:
* Future changes should refactor arguments into a struct
* This filtering only is supported by meilisearch right now
* Issue index number is bumped which will cause a re-index
Fix #25736
Caused by #24048
Right now we only check the activity type for `pull_request` event when
`types` is specified or there are no `types` and filter. If a workflow
only specifies filters but no `types` like this:
```
on:
pull_request:
branches: [main]
```
the workflow will be triggered even if the activity type is not one of
`[opened, reopened, sync]`. We need to check the activity type in this
case.
Co-authored-by: Giteabot <teabot@gitea.io>
Remove unnecessary `if opts.Logger != nil` checks.
* For "CLI doctor" mode, output to the console's "logger.Info".
* For "Web Task" mode, output to the default "logger.Debug", to avoid
flooding the server's log in a busy production instance.
Co-authored-by: Giteabot <teabot@gitea.io>
To record which command is slow, this PR adds a debug log for slow git
operations.
---------
Co-authored-by: Lauris BH <lauris@nix.lv>
Co-authored-by: delvh <dev.lh@web.de>
Fix regression of #5363 (so long ago).
The old code definded a document mapping for `issueIndexerDocType`, and
assigned it to `BleveIndexerData` as its type. (`BleveIndexerData` has
been renamed to `IndexerData` in #25174, but nothing more.) But the old
code never used `BleveIndexerData`, it wrote the index with an anonymous
struct type. Nonetheless, bleve would use the default auto-mapping for
struct it didn't know, so the indexer still worked. This means the
custom document mapping was always dead code.
The custom document mapping is not useless, it can reduce index storage,
this PR brings it back and disable default mapping to prevent it from
happening again. Since `IndexerData`(`BleveIndexerData`) has JSON tags,
and bleve uses them first, so we should use `repo_id` as the field name
instead of `RepoID`.
I did a test to compare the storage size before and after this, with
about 3k real comments that were migrated from some public repos.
Before:
```text
[ 160] .
├── [ 42] index_meta.json
├── [ 13] rupture_meta.json
└── [ 128] store
├── [6.9M] 00000000005d.zap
└── [256K] root.bolt
```
After:
```text
[ 160] .
├── [ 42] index_meta.json
├── [ 13] rupture_meta.json
└── [ 128] store
├── [3.5M] 000000000065.zap
└── [256K] root.bolt
```
It saves about half the storage space.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
Fixes #24723
Direct serving of content aka HTTP redirect is not mentioned in any of
the package registry specs but lots of official registries do that so it
should be supported by the usual clients.
This prevents the disk from overflowing with auth keys file
Fixes #17117
## ⚠️ BREAKING
This changes the default option for creating a backup of the authorized
key file when an update is made to default to false.
When branch's commit CommitMessage is too long, the column maybe too
short.(TEXT 16K for mysql).
This PR will fix it to only store the summary because these message will
only show on branch list or possible future search?
Resolve #24789
## ⚠️ BREAKING ⚠️
Before this, `DEFAULT_ACTIONS_URL` cound be set to any custom URLs like
`https://gitea.com` or `http://your-git-server,https://gitea.com`, and
the default value was `https://gitea.com`.
But now, `DEFAULT_ACTIONS_URL` supports only
`github`(`https://github.com`) or `self`(the root url of current Gitea
instance), and the default value is `github`.
If it has configured with a URL, an error log will be displayed and it
will fallback to `github`.
Actually, what we really want to do is always make it
`https://github.com`, however, this may not be acceptable for some
instances of internal use, so there's extra support for `self`, but no
more, even `https://gitea.com`.
Please note that `uses: https://xxx/yyy/zzz` always works and it does
exactly what it is supposed to do.
Although it's breaking, I belive it should be backported to `v1.20` due
to some security issues.
Follow-up on the runner side:
- https://gitea.com/gitea/act_runner/pulls/262
- https://gitea.com/gitea/act/pulls/70
This adds an API for uploading and Deleting Avatars for of Users, Repos
and Organisations. I'm not sure, if this should also be added to the
Admin API.
Resolves #25344
---------
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: Giteabot <teabot@gitea.io>
Related #14180
Related #25233
Related #22639
Close #19786
Related #12763
This PR will change all the branches retrieve method from reading git
data to read database to reduce git read operations.
- [x] Sync git branches information into database when push git data
- [x] Create a new table `Branch`, merge some columns of `DeletedBranch`
into `Branch` table and drop the table `DeletedBranch`.
- [x] Read `Branch` table when visit `code` -> `branch` page
- [x] Read `Branch` table when list branch names in `code` page dropdown
- [x] Read `Branch` table when list git ref compare page
- [x] Provide a button in admin page to manually sync all branches.
- [x] Sync branches if repository is not empty but database branches are
empty when visiting pages with branches list
- [x] Use `commit_time desc` as the default FindBranch order by to keep
consistent as before and deleted branches will be always at the end.
---------
Co-authored-by: Jason Song <i@wolfogre.com>
releated to #21820
- Split `Size` in repository table as two new colunms, one is `GitSize`
for git size, the other is `LFSSize` for lfs data. still store full size
in `Size` colunm.
- Show full size on ui, but show each of them by a `title`; example:
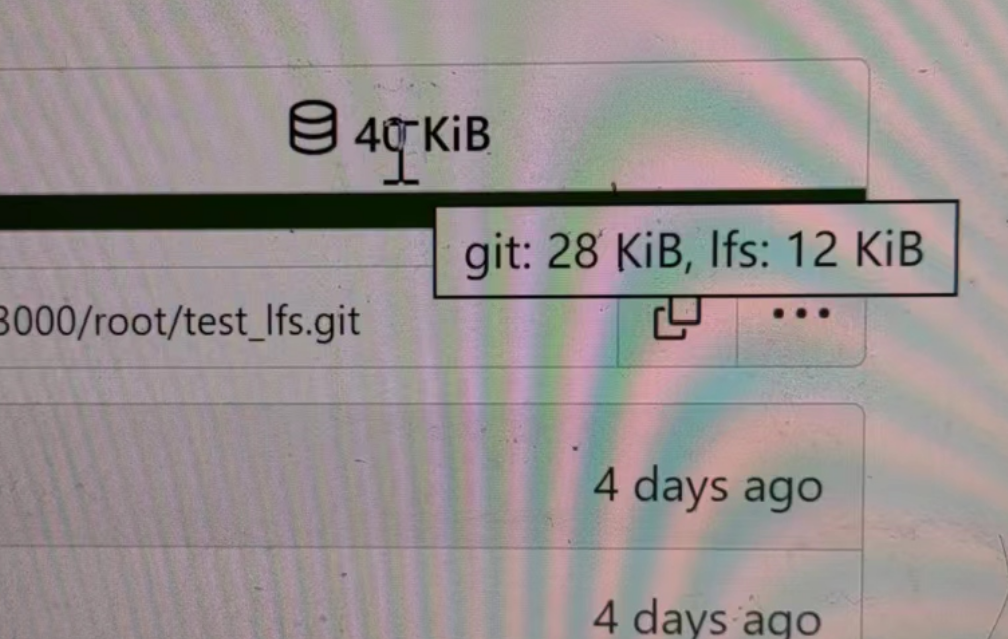
- Return full size in api response.
---------
Signed-off-by: a1012112796 <1012112796@qq.com>
Co-authored-by: Lunny Xiao <xiaolunwen@gmail.com>
Co-authored-by: silverwind <me@silverwind.io>
Co-authored-by: DmitryFrolovTri <23313323+DmitryFrolovTri@users.noreply.github.com>
Co-authored-by: Giteabot <teabot@gitea.io>
Fix #25451.
Bugfixes:
- When stopping the zombie or endless tasks, set `LogInStorage` to true
after transferring the file to storage. It was missing, it could write
to a nonexistent file in DBFS because `LogInStorage` was false.
- Always update `ActionTask.Updated` when there's a new state reported
by the runner, even if there's no change. This is to avoid the task
being judged as a zombie task.
Enhancement:
- Support `Stat()` for DBFS file.
- `WriteLogs` refuses to write if it could result in content holes.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
More fix for #24981
* #24981
Close #22361
* #22361
There were many patches for Gitea's sub-commands to satisfy the facts:
* Some sub-commands shouldn't output any log, otherwise the git protocol
would be broken
* Sometimes the users want to see "verbose" or "quiet" outputs
That's a longstanding problem, and very fragile. This PR is only a quick
patch for the problem.
In the future, the sub-command system should be refactored to a clear
solution.
----
Other changes:
* Use `ReplaceAllWriters` to replace
`RemoveAllWriters().AddWriters(writer)`, then it's an atomic operation.
* Remove unnecessary `syncLevelInternal` calls, because
`AddWriters/addWritersInternal` already calls it.
Co-authored-by: Giteabot <teabot@gitea.io>
Fix #25088
This PR adds the support for
[`pull_request_target`](https://docs.github.com/en/actions/using-workflows/events-that-trigger-workflows#pull_request_target)
workflow trigger. `pull_request_target` is similar to `pull_request`,
but the workflow triggered by the `pull_request_target` event runs in
the context of the base branch of the pull request rather than the head
branch. Since the workflow from the base is considered trusted, it can
access the secrets and doesn't need approvals to run.
Fix #25481
The `InitWorkPathAndCommonConfig` calls `LoadCommonSettings` which does
many checks like "current user is root or not".
Some commands like "environment-to-ini" shouldn't do such check, because
it might be run with "root" user at the moment (eg: the docker's setup
script)
ps: in the future, the docker's setup script should be improved to avoid
Gitea's command running with "root"
Fix regression of #25174.
The `Init` of the db indexer should return true to indicate that the
index was opened/existed, or the indexer will try to populate the index
(not really populate, just fill the queue, `Index` method of the db
indexer is a dummy).
Refactor `modules/indexer` to make it more maintainable. And it can be
easier to support more features. I'm trying to solve some of issue
searching, this is a precursor to making functional changes.
Current supported engines and the index versions:
| engines | issues | code |
| - | - | - |
| db | Just a wrapper for database queries, doesn't need version | - |
| bleve | The version of index is **2** | The version of index is **6**
|
| elasticsearch | The old index has no version, will be treated as
version **0** in this PR | The version of index is **1** |
| meilisearch | The old index has no version, will be treated as version
**0** in this PR | - |
## Changes
### Split
Splited it into mutiple packages
```text
indexer
├── internal
│ ├── bleve
│ ├── db
│ ├── elasticsearch
│ └── meilisearch
├── code
│ ├── bleve
│ ├── elasticsearch
│ └── internal
└── issues
├── bleve
├── db
├── elasticsearch
├── internal
└── meilisearch
```
- `indexer/interanal`: Internal shared package for indexer.
- `indexer/interanal/[engine]`: Internal shared package for each engine
(bleve/db/elasticsearch/meilisearch).
- `indexer/code`: Implementations for code indexer.
- `indexer/code/internal`: Internal shared package for code indexer.
- `indexer/code/[engine]`: Implementation via each engine for code
indexer.
- `indexer/issues`: Implementations for issues indexer.
### Deduplication
- Combine `Init/Ping/Close` for code indexer and issues indexer.
- ~Combine `issues.indexerHolder` and `code.wrappedIndexer` to
`internal.IndexHolder`.~ Remove it, use dummy indexer instead when the
indexer is not ready.
- Duplicate two copies of creating ES clients.
- Duplicate two copies of `indexerID()`.
### Enhancement
- [x] Support index version for elasticsearch issues indexer, the old
index without version will be treated as version 0.
- [x] Fix spell of `elastic_search/ElasticSearch`, it should be
`Elasticsearch`.
- [x] Improve versioning of ES index. We don't need `Aliases`:
- Gitea does't need aliases for "Zero Downtime" because it never delete
old indexes.
- The old code of issues indexer uses the orignal name to create issue
index, so it's tricky to convert it to an alias.
- [x] Support index version for meilisearch issues indexer, the old
index without version will be treated as version 0.
- [x] Do "ping" only when `Ping` has been called, don't ping
periodically and cache the status.
- [x] Support the context parameter whenever possible.
- [x] Fix outdated example config.
- [x] Give up the requeue logic of issues indexer: When indexing fails,
call Ping to check if it was caused by the engine being unavailable, and
only requeue the task if the engine is unavailable.
- It is fragile and tricky, could cause data losing (It did happen when
I was doing some tests for this PR). And it works for ES only.
- Just always requeue the failed task, if it caused by bad data, it's a
bug of Gitea which should be fixed.
---------
Co-authored-by: Giteabot <teabot@gitea.io>
this will allow us to fully localize it later
PS: we can not migrate back as the old value was a one-way conversion
prepare for #25213
---
*Sponsored by Kithara Software GmbH*
In modern days, there is no reason to make users set "charset" anymore.
Close #25378
## ⚠️ BREAKING
The key `[database].CHARSET` was removed completely as every newer
(>10years) MySQL database supports `utf8mb4` already.
There is a (deliberately) undocumented new fallback option if anyone
still needs to use it, but we don't recommend using it as it simply
causes problems.
{kind=link}
{kind=link}
{kind=link}
{kind=link}